📝 Paper Summary
Synthetic Data Generation
Reinforcement Learning for Reasoning
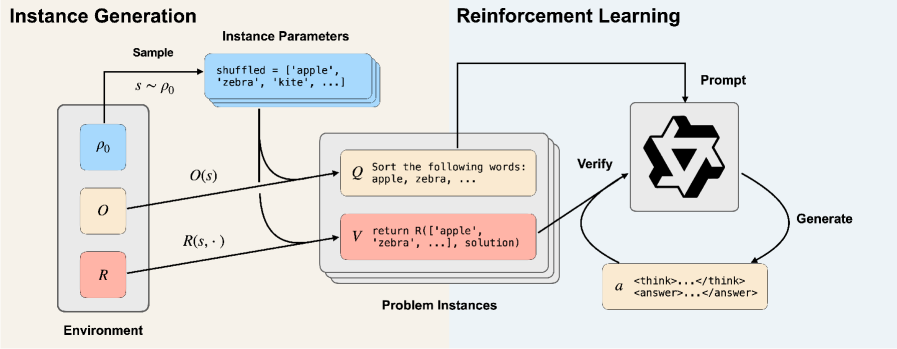
ReSyn autonomously generates diverse synthetic reasoning environments—complete with problem generators and code-based verifiers—to scale reinforcement learning for reasoning models beyond math and coding tasks.
Core Problem
Current RL training for reasoning relies on math/code tasks with ground truth or a few hand-crafted puzzle environments, limiting task diversity and the ability to generalize to broader logical reasoning.
Why it matters:
- Manual creation of reasoning environments is slow and labor-intensive, creating a bottleneck for scaling RL training data
- Restricting RL to math and code limits the diversity of reasoning patterns models can learn
- Self-generated reasoning chains (without verifiers) are unreliable for training because the teacher model may hallucinate incorrect steps or solutions
Concrete Example:
A model trained only on math might fail at a logic puzzle like 'dependency sorting' because it hasn't seen that specific reasoning structure. Manually coding a generator for every such puzzle is too costly. ReSyn automates this by having an LLM write the Python code for the generator and verifier.
Key Novelty
Autonomous Synthesis of Verifiable Reasoning Environments
- Instead of generating static Question-Answer pairs, ReSyn prompts an LLM to write Python code that defines a whole 'environment' (problem generator + solution verifier)
- Leverages the 'generator-verifier gap': it is often easier to verify a solution code-wise (e.g., check if a Sudoku grid is valid) than to solve it, allowing supervision on harder tasks
- Scales procedural data generation by creating hundreds of distinct environments (topics) rather than just scaling instance counts within a few hand-coded ones
Architecture
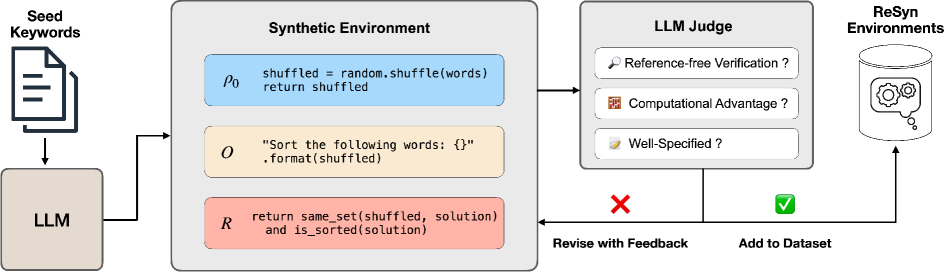
The ReSyn data generation pipeline, moving from topic keywords to functional code environments to final RL training data.
Evaluation Highlights
- +27% relative improvement on BBEH (Big-Bench Extra Hard) compared to the Qwen2.5-7B-Instruct baseline
- +14% relative improvement on BBH (Big-Bench Hard) compared to the Qwen2.5-7B-Instruct baseline
- 0-shot ReSyn model outperforms 3-shot Instruct baseline on BBH by nearly 5%, suggesting internalized reasoning capabilities
Breakthrough Assessment
8/10
Significantly expands the scope of RLVR by automating environment creation. The strong performance on out-of-domain benchmarks (BBEH) confirms that diverse synthetic logical tasks transfer to general reasoning.