📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Post-training for Reasoning
VI-CuRL stabilizes verifier-free reinforcement learning by using the model's intrinsic confidence to select easier, low-variance samples early in training, progressively introducing harder ones.
Core Problem
Verifier-free RL for reasoning suffers from destructive gradient variance because there are no external signals to prune incorrect trajectories, leading to training collapse.
Why it matters:
- Standard RLVR relies on ground-truth verifiers (e.g., math compilers), which are expensive or impossible to obtain for open-ended tasks like creative writing or general logic
- Without verifiers, the variance in gradients becomes unmanageably large, causing models to unlearn capabilities rather than improve
- Existing curriculum methods still depend on verifier signals, failing to address the core issue in truly verifier-independent settings
Concrete Example:
In verifier-free scenarios, standard Group Relative Policy Optimization (GRPO) treats all prompts equally. For a hard prompt where the model has high entropy (uncertainty), the sampled trajectories vary wildly in quality but lack reliable ground-truth feedback, resulting in noisy gradients that destabilize the policy.
Key Novelty
Intrinsic Confidence-Based Curriculum for RL
- Uses the model's own 'confidence' (length-normalized negative entropy) as a proxy for sample difficulty, independent of external verifiers
- Dynamically filters training batches to keep only high-confidence samples early on, ensuring gradients come from 'easy' problems where the model is decisive
- Gradually anneals the filtering threshold to include harder samples, provably ensuring the surrogate objective converges to the true unbiased objective over time
Architecture
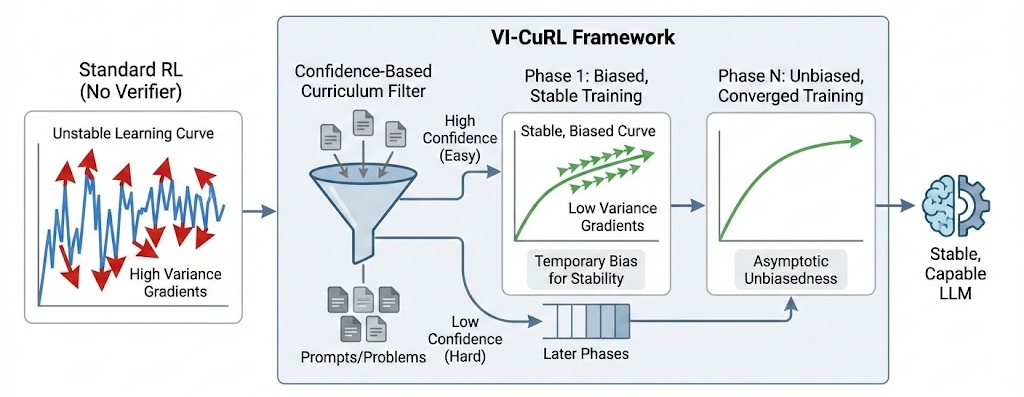
Illustration of the VI-CuRL framework contrasting it with standard RL.
Evaluation Highlights
- Consistently outperforms verifier-independent baselines across six logic and math benchmarks (e.g., GSM8K, MATH, logical deduction)
- Achieves performance competitive with oracle-verified methods (RLVR with ground truth) without using any external verifier during training
- Prevents the 'training collapse' observed in standard GRPO baselines, maintaining stability throughout the optimization process
Breakthrough Assessment
8/10
Offers a theoretically grounded and empirically effective solution to a critical bottleneck in RLHF/RLVR—dependence on external verifiers—making post-training scalable to open-ended domains.