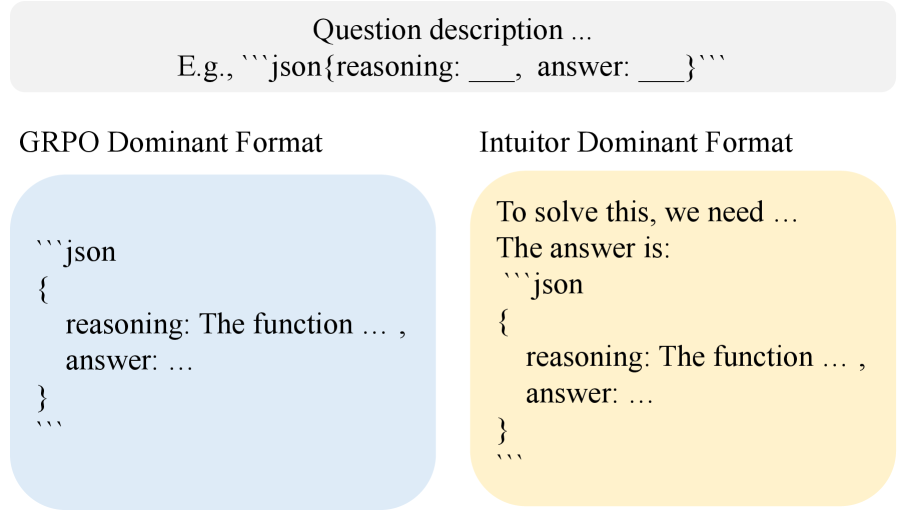
📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning
Intuitor improves LLM reasoning by using the model's own internal confidence (self-certainty) as the sole reward signal in reinforcement learning, eliminating the need for ground-truth labels or external verifiers.
Core Problem
Current RL methods for reasoning (RLVR) rely on expensive domain-specific verifiable rewards (like gold solutions or test cases), which limits scalability and generalization to open-ended tasks.
Why it matters:
- Gold-standard solutions and formal verification environments are unavailable for many real-world domains
- Outcome-based rewards (correct/incorrect) fail to incentivize the underlying reasoning process, limiting transferability
- Reliance on human supervision (RLHF) or crafted verifiers constrains autonomous self-improvement for super-human AI
Concrete Example:
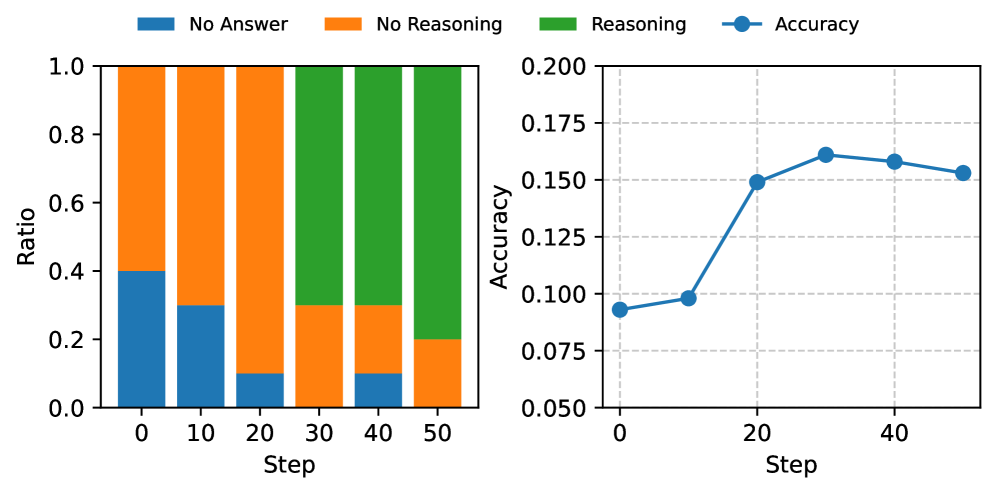
A model trained with standard RL on math problems might overfit to getting the final answer '42' correct without understanding the method. Intuitor rewards the model for being 'confident' in its generation steps, leading it to spontaneously develop detailed reasoning chains (like pre-code explanations) to increase its own certainty, even when not explicitly prompted to do so.
Key Novelty
Reinforcement Learning from Internal Feedback (RLIF) using Self-Certainty
- Replaces external correctness rewards with 'self-certainty'—a metric measuring how confident the model is in its own token predictions relative to a uniform guess
- Uses Group Relative Policy Optimization (GRPO) to encourage generation trajectories that maximize this intrinsic confidence, effectively rewarding the model for 'convincing itself'
Architecture
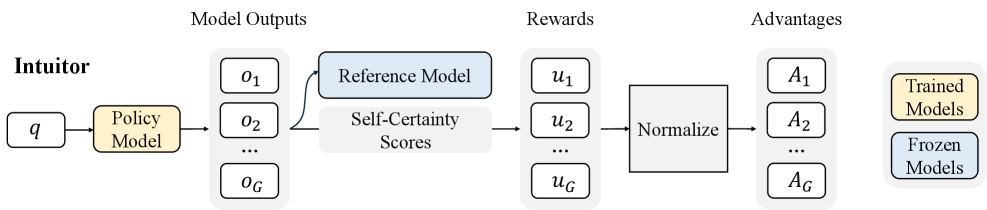
The Intuitor training pipeline integrating self-certainty with GRPO.
Evaluation Highlights
- Fine-tuned Qwen2.5-1.5B improves from 0% to 9.9% accuracy on LiveCodeBench solely by training on MATH data with intrinsic rewards
- Achieves 65% relative improvement on LiveCodeBench with Qwen2.5-3B compared to the base model, while supervised GRPO shows no improvement on this out-of-domain task
- Matches the performance of supervised RL (GRPO with gold answers) on in-domain MATH benchmarks without using any ground truth labels
Breakthrough Assessment
8/10
Demonstrates that internal model signals can substitute for external supervision in reasoning tasks, achieving strong generalization and competitive performance. A significant step toward autonomous self-improving AI.