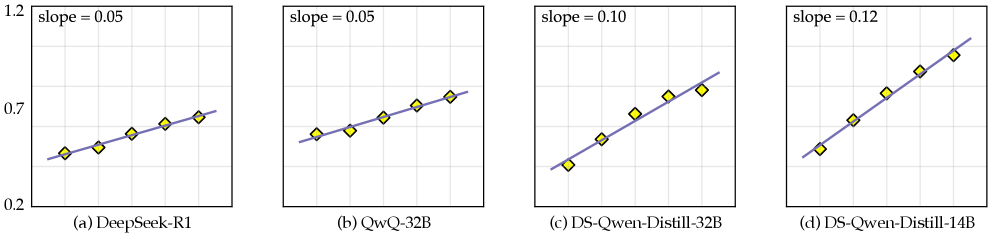
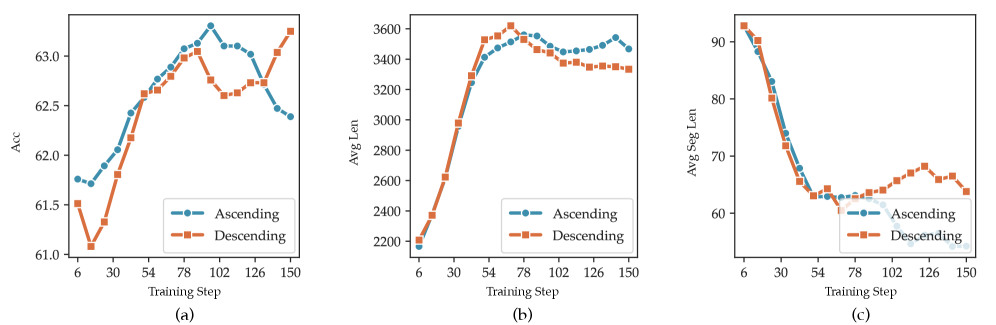
📝 Paper Summary
Large Reasoning Models (LRMs)
Reinforcement Learning from Verifier Reward (RLVR)
The paper introduces Group Relative Segment Penalization (GRSP), a method to reduce excessive reasoning in Large Reasoning Models by penalizing redundant steps rather than individual tokens, using length-aware weighting to preserve accuracy.
Core Problem
Large Reasoning Models trained with RLVR tend to 'overthink,' generating excessively long and meandering reasoning trajectories that inflate computational costs without improving accuracy.
Why it matters:
- Existing token-level penalties (like length ratios) are too coarse, often disrupting the learning of valid reasoning patterns and degrading task performance
- Identifying redundant content at the token level is ambiguous and difficult for verifiers, leading to unstable RL training
- Test-time scaling benefits are lost if models are simply forced to be short without understanding which parts of the reasoning are actually redundant
Concrete Example:
When solving a math problem, a model might repeatedly explore and revise paths (overthinking), generating hundreds of unnecessary tokens. Token-level penalties might force it to truncate valid reasoning, causing it to fail, whereas a human would simply identify and remove entire redundant 'steps' or segments.
Key Novelty
Group Relative Segment Penalization (GRSP)
- Shifts supervision granularity from tokens to reasoning segments (steps), which correlate better with redundancy and are easier to assess
- Applies a 'descending' weighting scheme where shorter segments are penalized more heavily than longer ones, encouraging deep thinking within fewer steps rather than rapid, shallow, redundant steps
Architecture
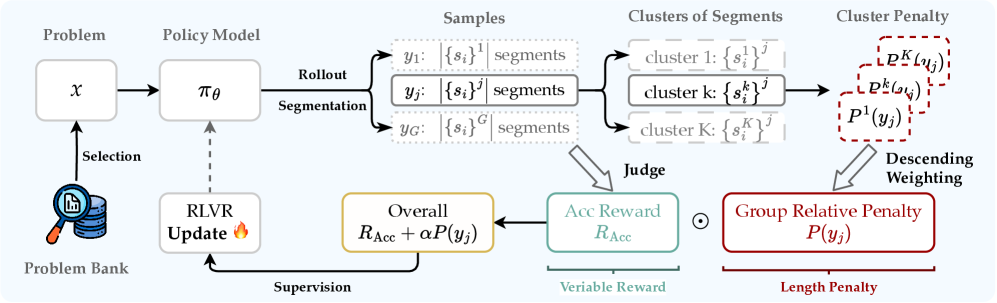
The workflow of GRSP. It illustrates sampling a response group, segmenting the reasoning into steps, clustering segments by length, calculating z-score penalties for each cluster, applying descending weights, and summing them into the final reward.
Evaluation Highlights
- Achieves highest accuracy (64.88%) and lowest token count (2155) on Omni-MATH 500 using Reinforce + GRSP, surpassing both standard Reinforce and length-penalty baselines
- Reduces average reasoning segments from 26.66 (Reinforce) to 21.07 (GRSP) on keyword-based segmentation analysis, effectively pruning redundancy
- Demonstrates scalability: On Qwen-2.5-32B-it, GRSP significantly reduces token usage while maintaining near-identical accuracy compared to standard RL baselines
Breakthrough Assessment
7/10
Offers a practical, statistically grounded solution to the specific 'overthinking' problem in LRMs. While a refinement of RLVR rather than a new paradigm, it effectively balances efficiency and accuracy where previous methods failed.