📝 Paper Summary
Explainable Recommendation
Graph Retrieval-Augmented Generation (GraphRAG)
G-Refer combines path-level and node-level graph retrieval with a knowledge pruning mechanism to help Large Language Models generate explicit, accurate, and stable explanations for recommendations.
Core Problem
Existing methods struggle to extract collaborative filtering (CF) information from complex graphs and effectively integrate these implicit, structured signals into LLMs for textual explanations.
Why it matters:
- LLMs alone lack the specific collaborative context to explain *why* a user likes an item
- Implicit GNN embeddings are opaque and hard to interpret, making it difficult to verify the logic behind a recommendation
- There is a modality gap between structured graph data (nodes/edges) and the natural language generation required for user-facing explanations
Concrete Example:
A GNN might predict a user likes 'Doctor Strange' because of an embedding dot product. However, it fails to explicitly tell the LLM that the user previously watched 'Iron Man' (path connection) or likes the actor Benedict Cumberbatch (semantic connection), leading the LLM to hallucinate generic reasons rather than citing specific evidence.
Key Novelty
Hybrid Graph Retrieval with Knowledge Pruning
- Retrieves collaborative filtering signals from two perspectives: 'Path-level' (structural connections like User->Item->User->Item) and 'Node-level' (semantic similarities based on text profiles)
- Translates these retrieved graph components into flattened natural language text to prompt the LLM
- Filters out 'easy' training samples where the profile alone is sufficient (Knowledge Pruning), forcing the model to learn from cases where graph knowledge is actually necessary
Architecture
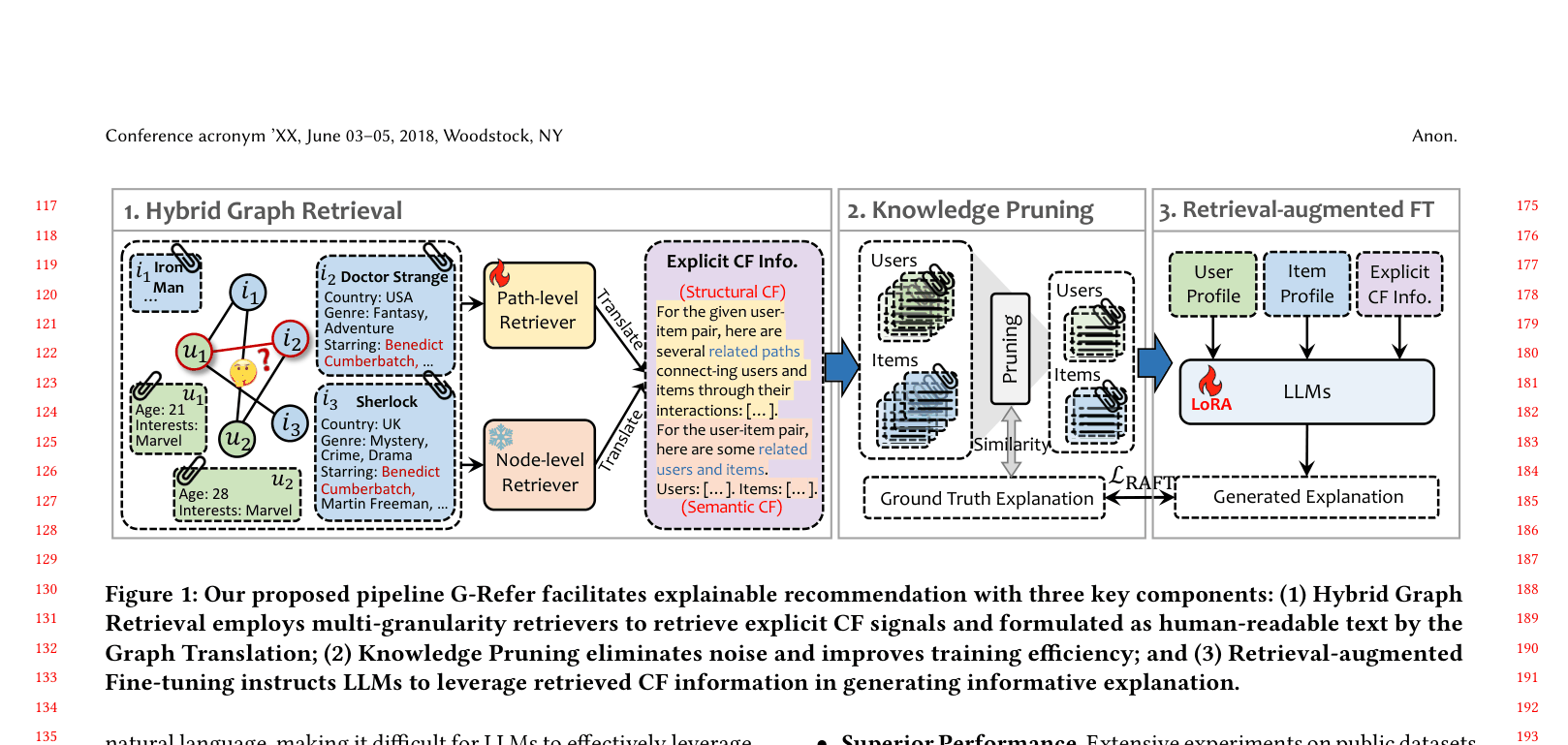
The overall G-Refer pipeline, illustrating the flow from user-item input to explanation generation via hybrid retrieval.
Evaluation Highlights
- +8.67% improvement in BERT-Recall on the Yelp dataset compared to the strongest baseline (XRec)
- +7.48% improvement in BERT-Recall on Google-reviews compared to XRec, indicating better coverage of key explanation information
- Achieves higher stability (lower standard deviation) across GPT, BERT, and BART metrics compared to baselines like PEPLER and PETER
Breakthrough Assessment
7/10
Strong empirical results and a well-motivated architecture combining structural and semantic retrieval. The knowledge pruning idea for RAG training is a practical insight.