📊 Experiments & Results
Evaluation Setup
Multimodal reasoning across diverse domains (General, Math, Geometry)
Benchmarks:
- MMMU (General multimodal reasoning)
- MathVista (Multimodal mathematical reasoning)
- MathVerse (Geometric and mathematical reasoning)
- MMMU-Pro (Advanced multimodal reasoning)
- MATH-Vision (Visual math problems)
- WeMATH (Math reasoning)
Metrics:
- Accuracy (Average across benchmarks)
- Inconsistency Rate (Faithfulness)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison shows AutoRubric-R1V significantly outperforming the base model and achieving parity with much larger models. | ||||
| Average (6 benchmarks) | Accuracy | 47.29 | 54.81 | +7.52 |
| Average (6 benchmarks) | Accuracy | 55.57 | 54.81 | -0.76 |
| Average (6 benchmarks) | Accuracy | 52.96 | 54.81 | +1.85 |
Experiment Figures
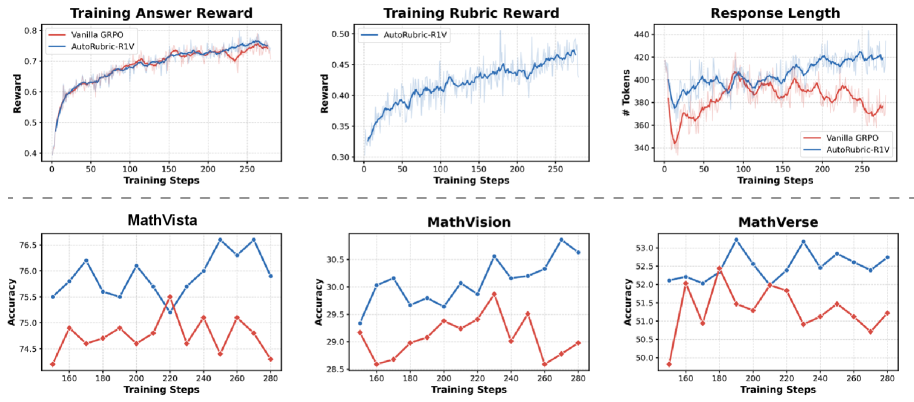
Training dynamics comparing AutoRubric-R1V vs Vanilla GRPO across Answer Reward, Rubric Reward, and Response Length.

Case study comparing two trajectories (one with logical errors, one correct) and the rubric scoring.
Main Takeaways
- Rubric-based rewards stabilize training: Unlike Vanilla RLVR which oscillates/degrades due to reward hacking, AutoRubric shows steady improvement in reward curves.
- Problem-specific rubrics are essential: The 'w/o Rubric' ablation (judge without specific criteria) performed significantly worse, comparable to Vanilla RLVR, proving that generic 'is this good?' prompts are insufficient.
- Self-aggregation works: Generating rubrics from the model's own correct trajectories (test-time scaling intuition) provides high-quality supervision without human labels.