📝 Paper Summary
Reinforcement Learning for Reasoning
Data Selection / Curriculum Learning
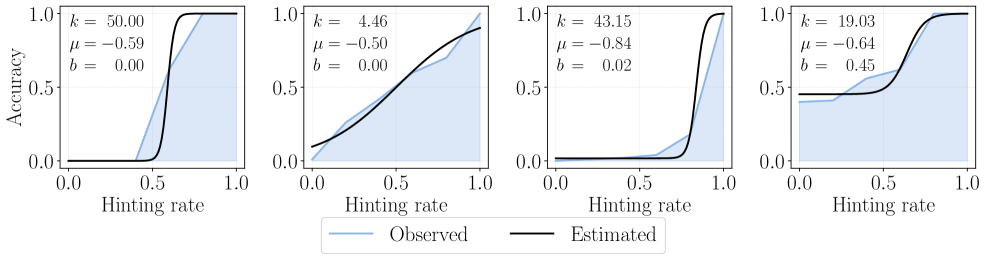
SEELE optimizes reasoning training by dynamically adjusting the length of solution hints via Item Response Theory to keep problem difficulty at a theoretical 'sweet spot' of 50% accuracy.
Core Problem
RLVR training is inefficient because static problem difficulties often mismatch the model's evolving capability: overly hard problems yield zero reward (no learning), while overly easy problems yield low advantage signals.
Why it matters:
- Standard on-policy exploration relies on the model stumbling upon correct answers; if the success rate is near zero, gradients vanish and learning stalls
- Existing hint-based methods use static prefixes that do not adapt to the specific instance or the model's real-time capability, leading to suboptimal difficulty (either too much hand-holding or not enough)
- RL often fails to teach new capabilities, merely amplifying existing ones; efficient exploration is required to bridge the gap to harder reasoning tasks
Concrete Example:
For a complex math problem, a standard model might fail 100% of the time (0 reward). A static hint method might reveal 90% of the solution, making the completion trivial (100% accuracy, low gradient). SEELE calculates that revealing exactly 40% of the solution results in 50% accuracy, maximizing the learning signal.
Key Novelty
Capability-Adaptive Hint Scaffolding (SEELE)
- Theoretically identifies that learning efficiency is maximized when rollout accuracy is exactly 50% (the 'sweet spot' of the quadratic loss envelope)
- Uses a multi-round sampling strategy where an Item Response Theory (IRT) model predicts the optimal hint length for the next round based on accuracy feedback from previous rounds
- Dynamically scaffolds each training instance in real-time, reducing hint length as the model becomes more capable throughout training
Architecture
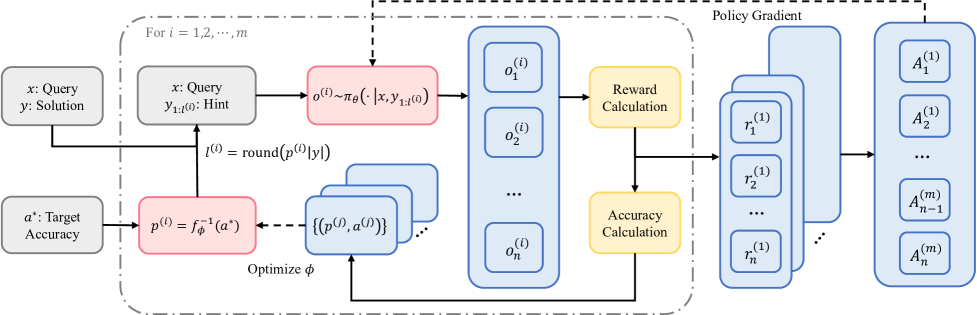
The multi-round adaptive sampling framework of SEELE.
Evaluation Highlights
- Outperforms GRPO (Group Relative Policy Optimization) by +11.8 points on average across six math reasoning benchmarks
- Surpasses Supervised Fine-tuning (SFT) by +10.5 points on average
- Beats the best previous supervision-aided RL approach by +3.6 points on average
Breakthrough Assessment
8/10
Provides a strong theoretical grounding for difficulty adjustment in RLVR and a practical, effective implementation using IRT. Significant empirical gains over strong baselines like GRPO.