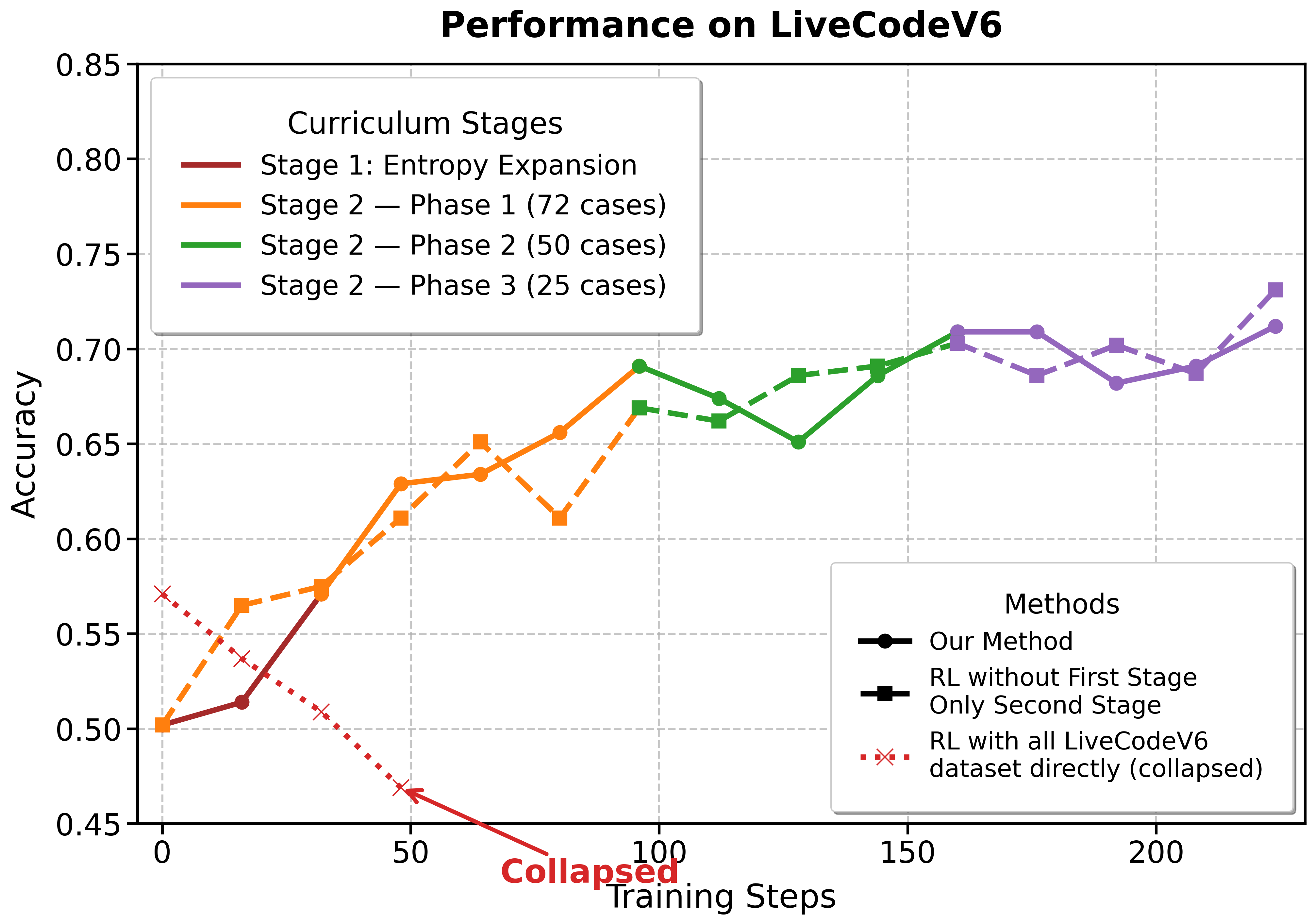
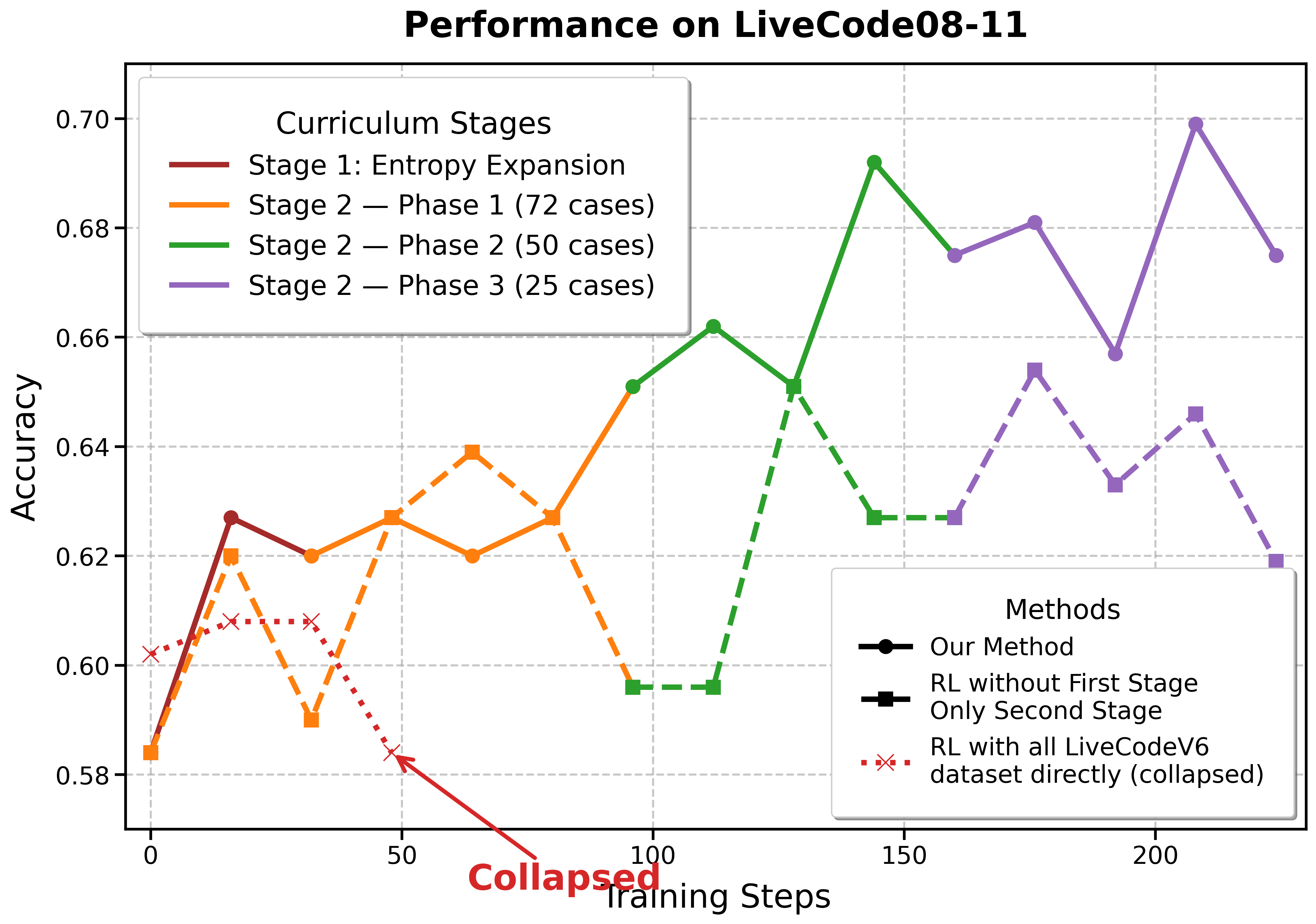
📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Competitive Programming Code Generation
DRIVE is a two-stage reinforcement learning framework that first expands output diversity on medium problems and then uses a hard-focus curriculum with large rollout budgets to master difficult competitive programming tasks.
Core Problem
Standard RLVR struggles to learn difficult competitive programming problems because models quickly converge to low-entropy simple modes or fail to explore complex solutions effectively when training uniformly across all difficulties.
Why it matters:
- Competitive programming requires handling strict edge cases and long reasoning chains, which are hard to learn from simple SFT (Supervised Fine-Tuning) data
- Uniform RL training wastes compute on easy problems while failing to generate valid training signals for hard ones due to insufficient exploration (rollouts)
- Existing work focuses on math benchmarks (AIME) or algorithms, neglecting data curation strategies for code generation
Concrete Example:
When trained with standard RL, the model exhibits low entropy and repetitive patterns (e.g., loops leading to truncation) on hard Codeforces problems. It fails to generate a single correct solution even after many steps because the exploration budget (rollouts) is too small to find a sparse successful path.
Key Novelty
Two-Stage Entropy-Then-Focus RL Training
- Stage 1 (Entropy Expansion): Trains on a diverse set of medium-difficulty problems with moderate exploration to increase the model's output variety and stop it from collapsing into repetitive failure modes.
- Stage 2 (Hard-Focus Curriculum): Filters the dataset to keep only the hardest problems and drastically increases the exploration budget (rollouts), forcing the model to find solutions for the 'long tail' of difficulty.
Architecture
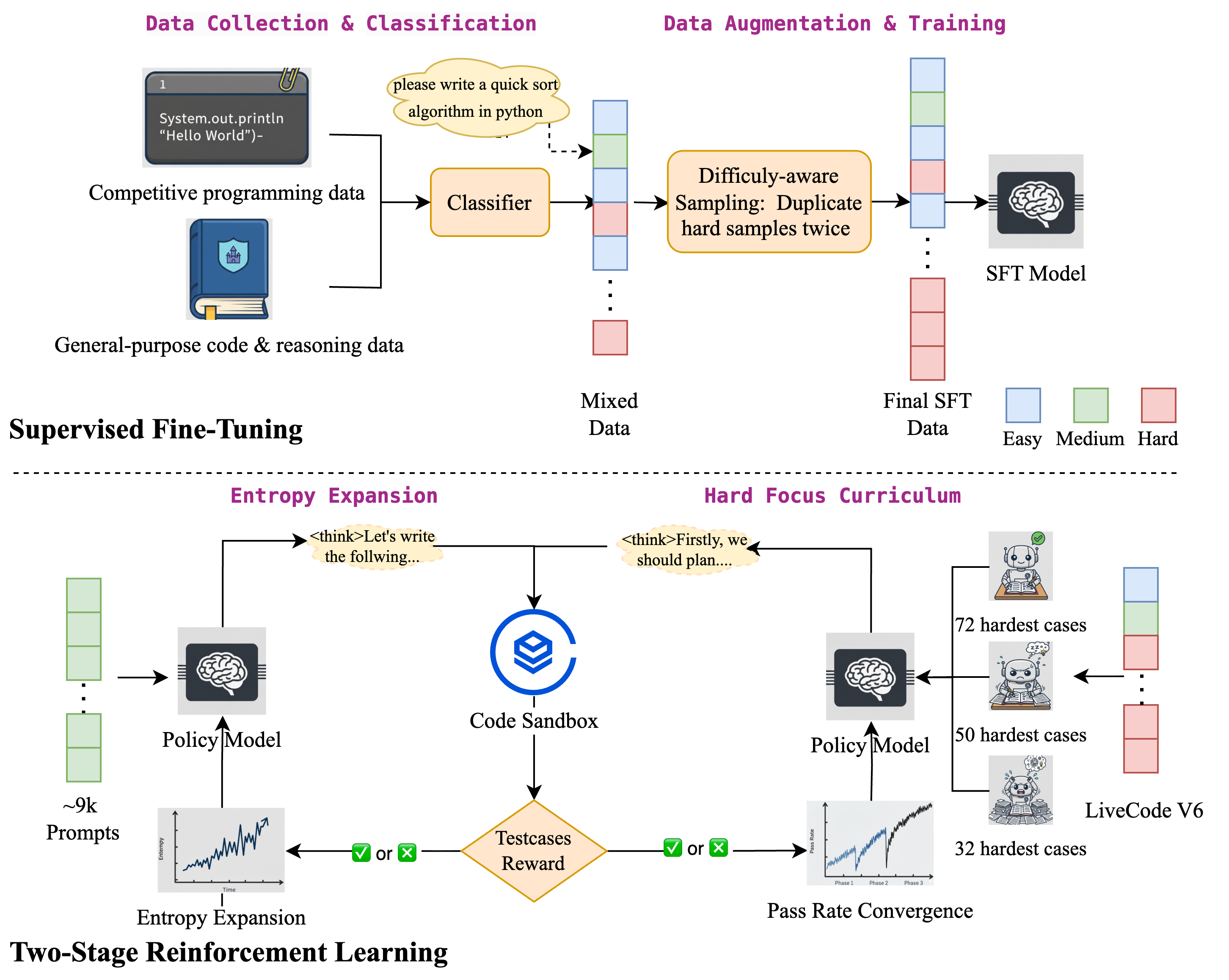
The overall training pipeline of DRIVE, illustrating the transition from SFT to two distinct RL stages.
Evaluation Highlights
- +58.3% relative improvement on Codeforces Weekly OJ compared to the SFT baseline, achieving state-of-the-art among 32B models
- Achieves 0.182 Pass Rate on Codeforces, outperforming the previous best 32B model (OpenReasoning-Nemotron-32B at 0.132) by a significant margin
- Comparable performance to much larger models like DeepSeek-V3.1 on LiveCode benchmarks despite having only 32B parameters
Breakthrough Assessment
8/10
Strong practical contribution demonstrating that data curation (curriculum and difficulty focusing) is as critical as algorithms in RLVR. The performance gains on hard benchmarks are substantial for the model size.