📝 Paper Summary
GUI Agents
Reinforcement Learning with Verifiable Rewards (RLVR)
Imitation Learning
BEPA improves end-to-end GUI agents by re-rolling expert plans to make them policy-reachable and injecting them into reinforcement learning only when on-policy exploration fails.
Core Problem
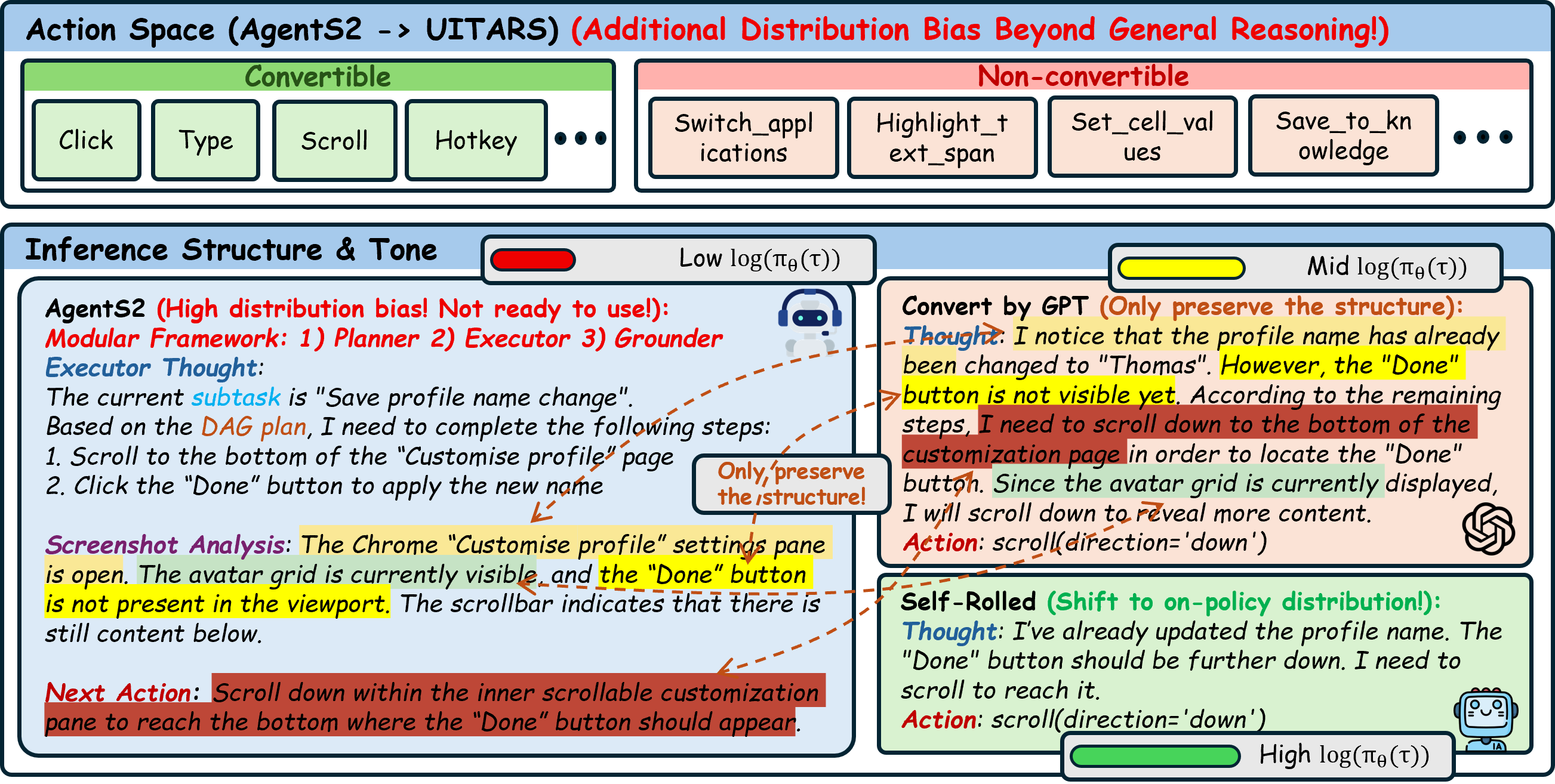
Training end-to-end GUI agents using expert traces from framework-based systems fails due to structural mismatch (different action spaces) and distribution shift (expert trajectories lie off the student's manifold).
Why it matters:
- High-quality interactive GUI environments (like OSWorld) are scarce and hard to scale, limiting on-policy exploration data
- Naive mixing of off-policy expert data into on-policy algorithms like GRPO causes optimization instability and exploration collapse due to the covariate shift
- End-to-end policies lag significantly behind framework-based agents on complex benchmarks, limiting their deployment utility
Concrete Example:
An expert framework agent might solve a task using precise API calls or high-level tool usage. If a naive end-to-end agent tries to imitate this trace directly, it fails because it operates on raw screenshots and low-level mouse clicks, creating a 'structural mismatch' where the expert's path is unintelligible or unreachable for the student.
Key Novelty
Bi-Level Expert-to-Policy Assimilation (BEPA)
- Level 1 (Self-Rolled Execution): Converts abstract expert plans into 'reachable' trajectories by forcing the base policy to execute the plan itself, discarding failures and keeping only traces the student can actually perform
- Level 2 (Dynamic Assimilation): Integrates these traces into GRPO (Group Relative Policy Optimization) using a dynamic cache that updates with the student's own emerging successes, injecting guidance only when the student completely fails a task
Architecture
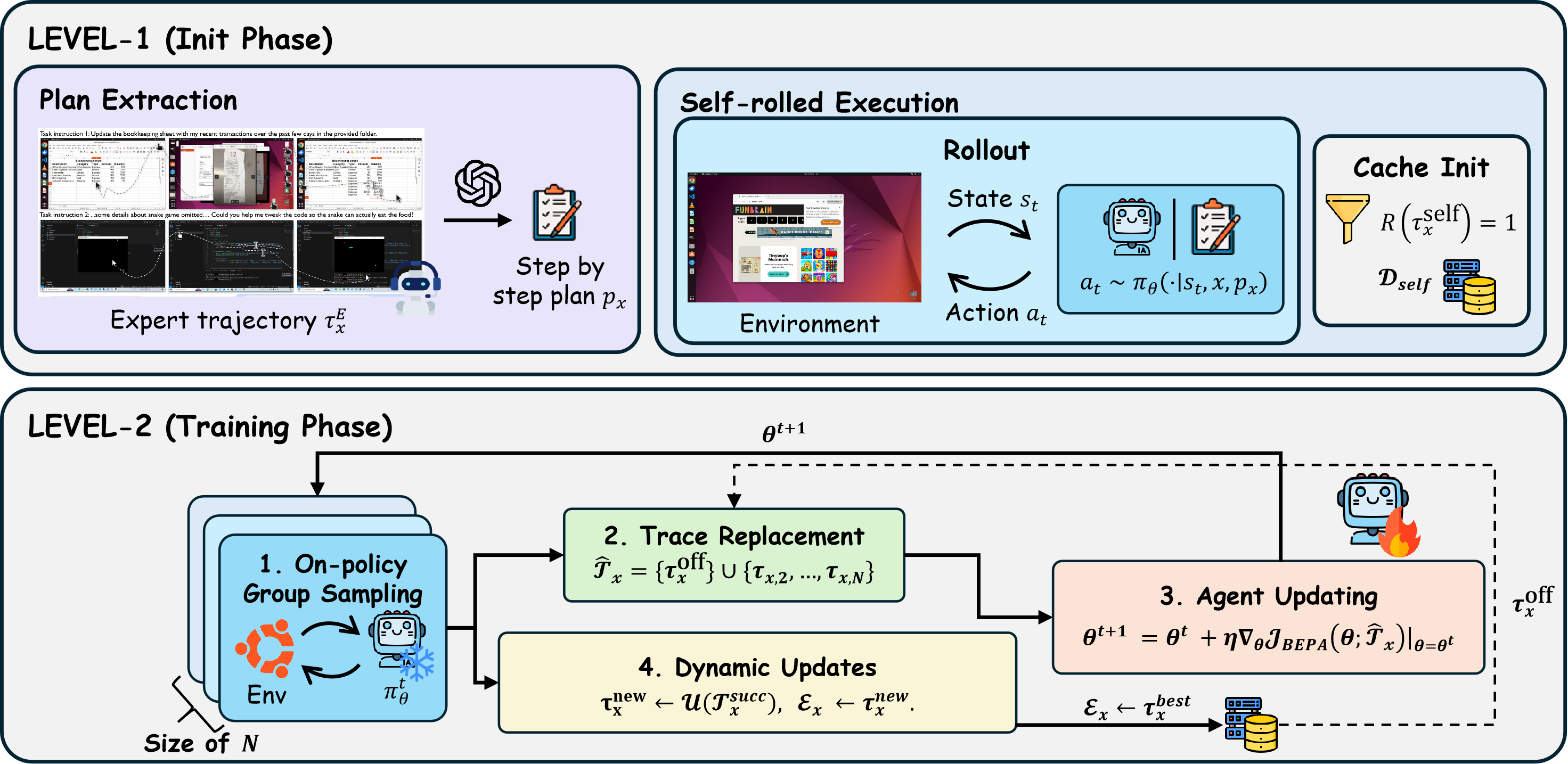
The BEPA framework pipeline showing the two levels of assimilation during training.
Evaluation Highlights
- Achieves 32.13% success on OSWorld-Verified, improving the base UITARS1.5-7B model by +9.26 percentage points (+40.5% relative)
- Doubles performance on the strictly held-out test split from 5.74% to 10.30%, demonstrating strong generalization beyond training tasks
- Outperforms standard GRPO (+8.53 points) and naive expert integration methods (SFT, mixed training) across multiple benchmarks including MMBench-GUI and Online-Mind2Web
Breakthrough Assessment
8/10
Significantly closes the gap between end-to-end and framework-based GUI agents. The bi-level assimilation strategy offers a principled way to use off-policy data in on-policy RL without destabilizing training.