📝 Paper Summary
Reinforcement Learning for Reasoning
LLM Post-training
RLTR enhances reasoning robustness by rewarding the generator when its truncated reasoning prefix allows a separate receiver model to successfully solve the problem.
Core Problem
Reinforcement Learning with Verifiable Rewards (RLVR) optimizes only final-answer correctness, often producing brittle or idiosyncratic reasoning traces that fail to generalize or transfer.
Why it matters:
- Models optimized solely for outcome correctness (RLVR) show degraded consistency (Maj@K) as the number of samples increases
- Robust reasoning should be reusable and interpretable by others, not just a lucky path to the right answer found by a specific model
- Current methods lack incentives for intermediate reasoning quality without expensive step-level human annotations (PRMs)
Concrete Example:
On MATH-500, a standard RLVR model achieves high single-sample accuracy but its consistency drops at high sample counts (Maj@16 drops from 81.2 base to 80.2 RLVR). This indicates the reasoning is fragile; RLTR fixes this by ensuring prefixes are stable enough for a second model to complete.
Key Novelty
Reinforcement Learning with Transferable Reward (RLTR)
- Operationalizes 'reasoning quality' as 'transferability': a reasoning trace is robust if a different model (Receiver) can finish it correctly after it is truncated.
- Introduces a Transfer Reward computed by truncating the Generator's output and checking if the Receiver reaches the correct answer from that prefix.
- Combines standard answer correctness rewards with this new transfer signal to optimize the Generator via Group Relative Policy Optimization (GRPO).
Architecture
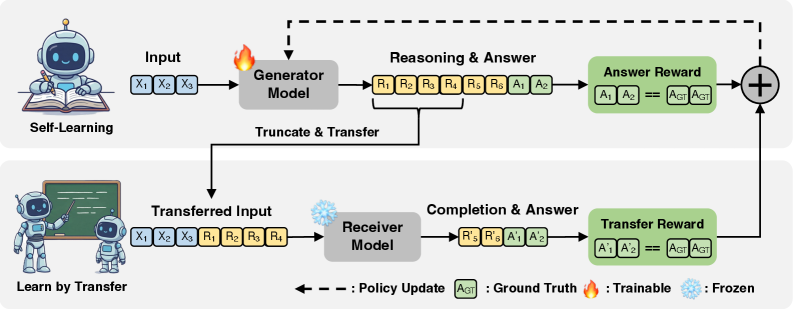
Overview of the RLTR framework comparing it to standard RLVR. Shows the pipeline where generator output is truncated and passed to a receiver.
Evaluation Highlights
- +5.8 points in Maj@64 on the AMC23 benchmark compared to RLVR (61.7% to 67.5%), demonstrating superior consistency.
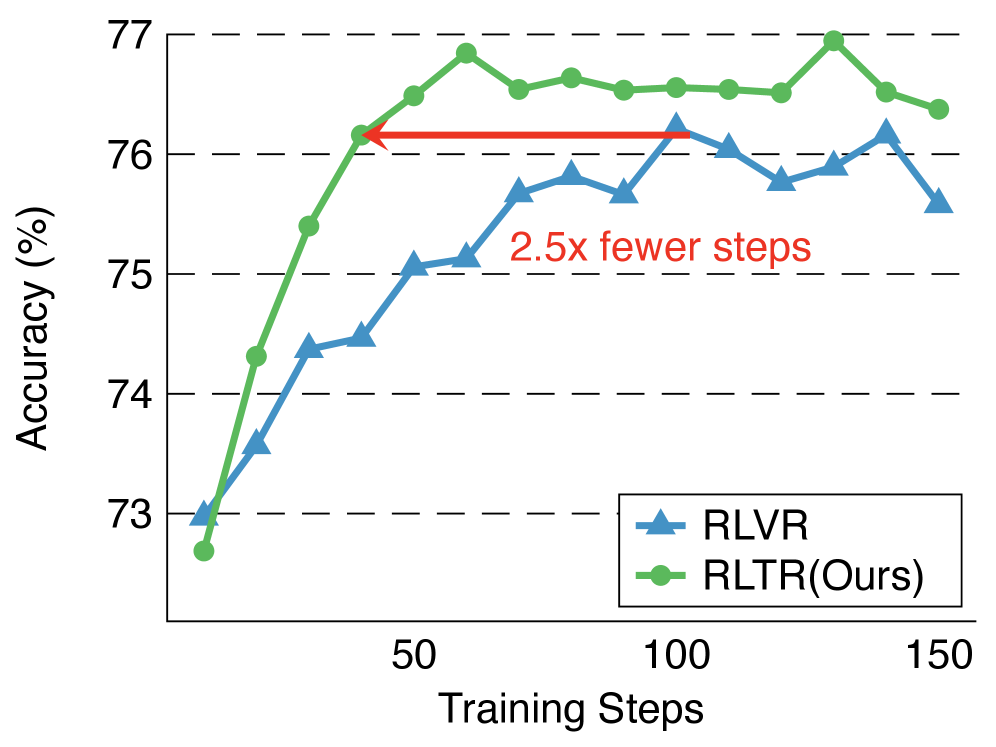
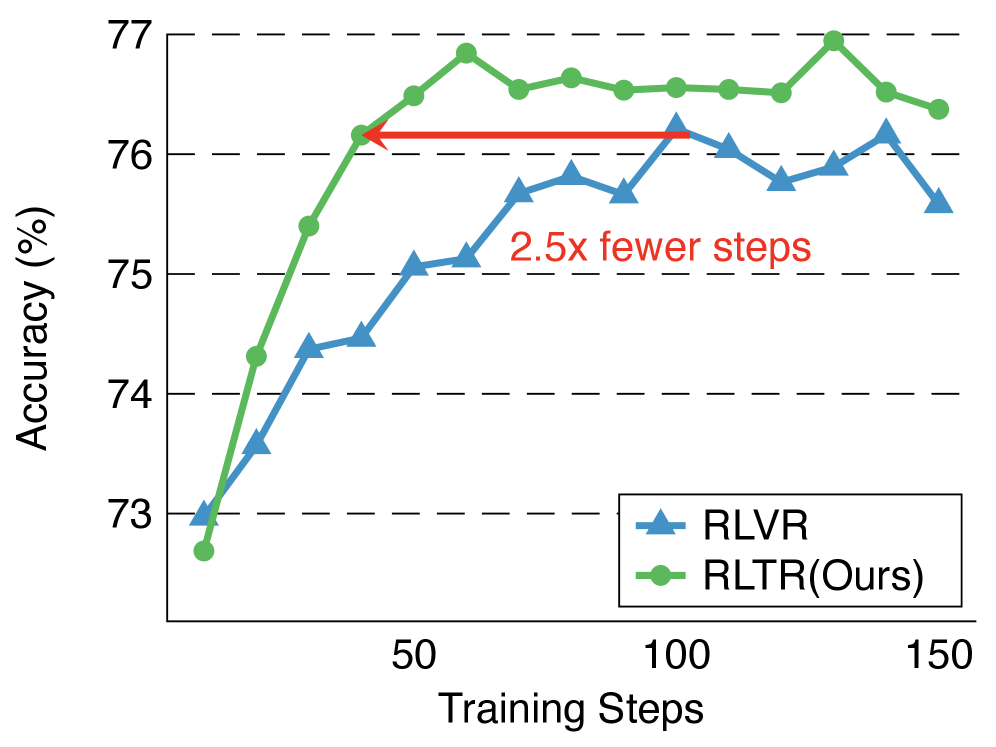
- Matches RLVR's average accuracy on MATH-500 with approximately 2.5x fewer training steps, indicating significantly higher sample efficiency.
- +4.4 points in Maj@64 on AIME 2024 (16.7% to 21.1%) and +5.0 points in average accuracy (9.8% to 14.8%) compared to RLVR.
Breakthrough Assessment
8/10
A clever, supervision-free method to enforce process quality. By using a second model as a verifier of 'explainability', it improves robustness and efficiency without human process labels.