📊 Experiments & Results
Evaluation Setup
Complex Question Answering over Knowledge Graphs with simulated incompleteness (random triple removal).
Benchmarks:
- WebQuestionSP (WebQSP) (Multi-hop QA (up to 2 hops))
- Complex WebQuestions (CWQ) (Multi-hop QA (up to 4 hops))
- MetaQA-3hop (Multi-hop QA (Movie domain))
Metrics:
- Hits@1
- Accuracy
- F1 Score
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| SymAgent (Qwen2-7B) outperforms strong baselines and GPT-4 across all datasets. | ||||
| WebQSP | Hits@1 | 54.25 | 78.54 | +24.29 |
| CWQ | Hits@1 | 41.46 | 58.86 | +17.40 |
| MetaQA-3hop | F1 | 12.61 | 25.76 | +13.15 |
| Self-learning effectiveness compared to distillation. | ||||
| CWQ | Hits@1 | 54.43 | 58.86 | +4.43 |
Experiment Figures
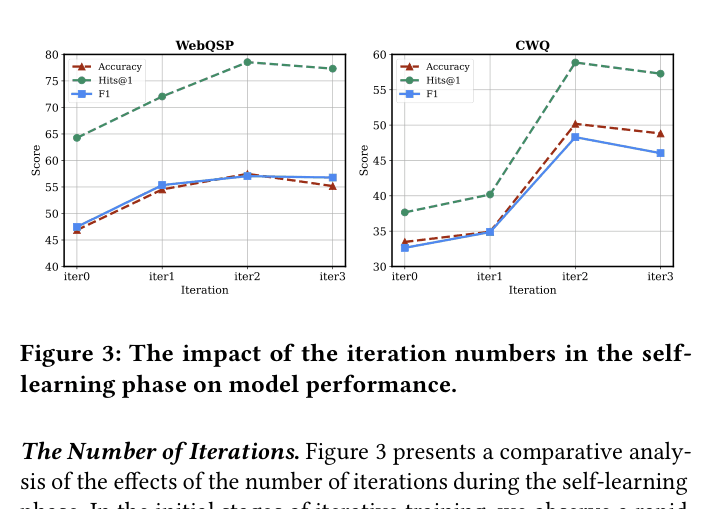
Impact of iteration numbers in the self-learning phase on WebQSP and CWQ performance.
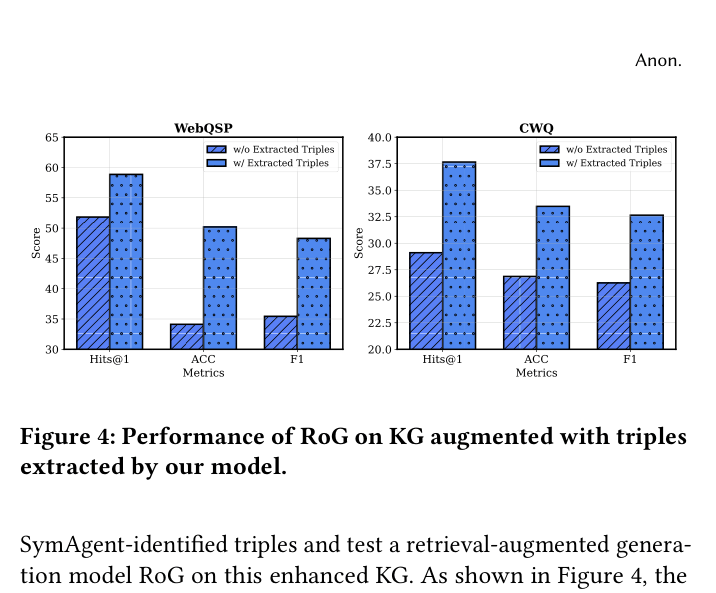
Performance of RoG (baseline) when the KG is augmented with triples extracted by SymAgent.
Main Takeaways
- SymAgent with weak backbones (7B) achieves better or comparable performance to GPT-4 on complex reasoning tasks.
- The Planner module is crucial; removing it drops Hits@1 on WebQSP from 78.54% to 64.37%.
- Self-learning with self-refinement is more effective than distilling from GPT-4, likely due to better distribution matching and reduced hallucination.
- The model successfully identifies missing triples in KGs, validating its ability to perform automatic KG completion during reasoning.