📝 Paper Summary
LLM Reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
Mechanistic Interpretability
The authors propose that RLVR-trained LLMs organize knowledge into a sparse 'concept web' with an average degree of two, explaining anomalous training behaviors and enabling a targeted 'annealing' intervention to boost reasoning.
Core Problem
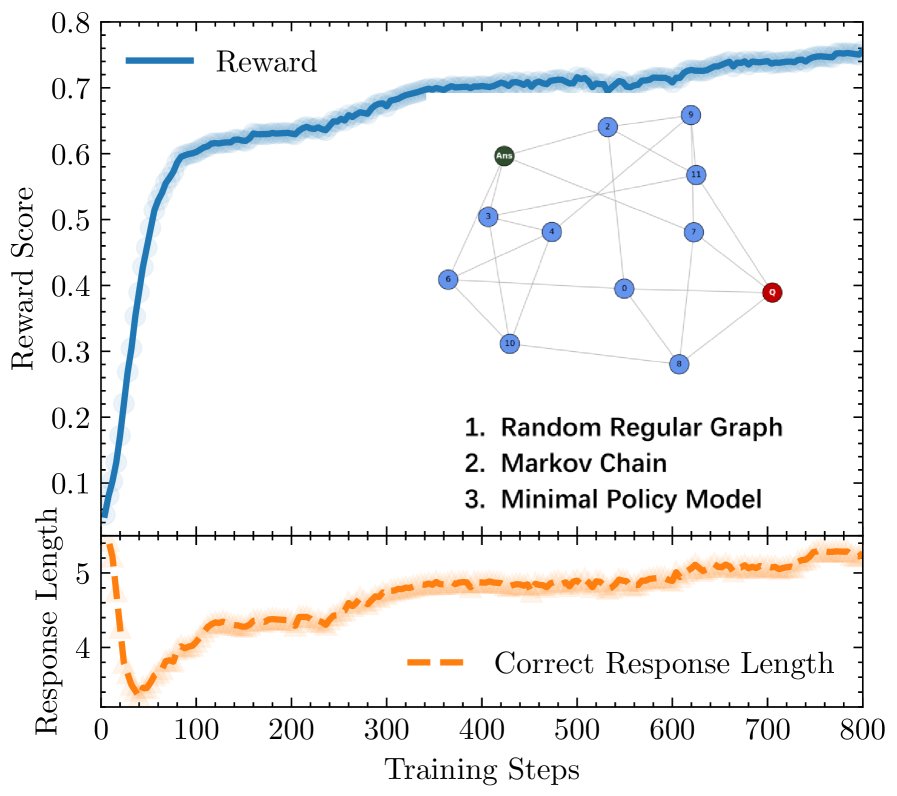
Training LLMs with Reinforcement Learning with Verifiable Rewards (RLVR) leads to puzzling behaviors like V-shaped response length trajectories, plateauing performance, and extreme vulnerability to catastrophic forgetting.
Why it matters:
- Standard explanations are fragmented, lacking a unifying framework that ties disparate phenomena (forgetting, plateaus, collapse) to a common underlying structure
- Current reasoning models suffer from 'policy collapse' where exploration freezes into rigid, high-reward trajectories, limiting generalization
- Catastrophic forgetting in reasoning models is particularly severe, making it difficult to combine RLVR with subsequent supervised fine-tuning
Concrete Example:
When an RLVR-trained model undergoes lightweight supervised fine-tuning (SFT), its reasoning capabilities abruptly degrade (catastrophic forgetting). The paper shows this isn't global erasure but the severing of critical 'trunk' edges in a sparse web, disconnecting vast sub-trees of knowledge.
Key Novelty
Sparse Concept Web Hypothesis & Annealed-RLVR
- Models the LLM's latent reasoning structure as a 'concept web' that self-organizes into a sparse graph with an average degree of ~2, meaning it is largely tree-like and fragile
- Explains the V-shaped response length: initial drop is local skill optimization (finding short paths on islands), subsequent rise is global integration (navigating the growing sparse web requires longer paths)
- Proposes 'Annealed-RLVR': a training algorithm that injects a targeted SFT 'heating' step at the 'maximally frustrated state' (where islands struggle to connect) to resolve topological bottlenecks
Architecture
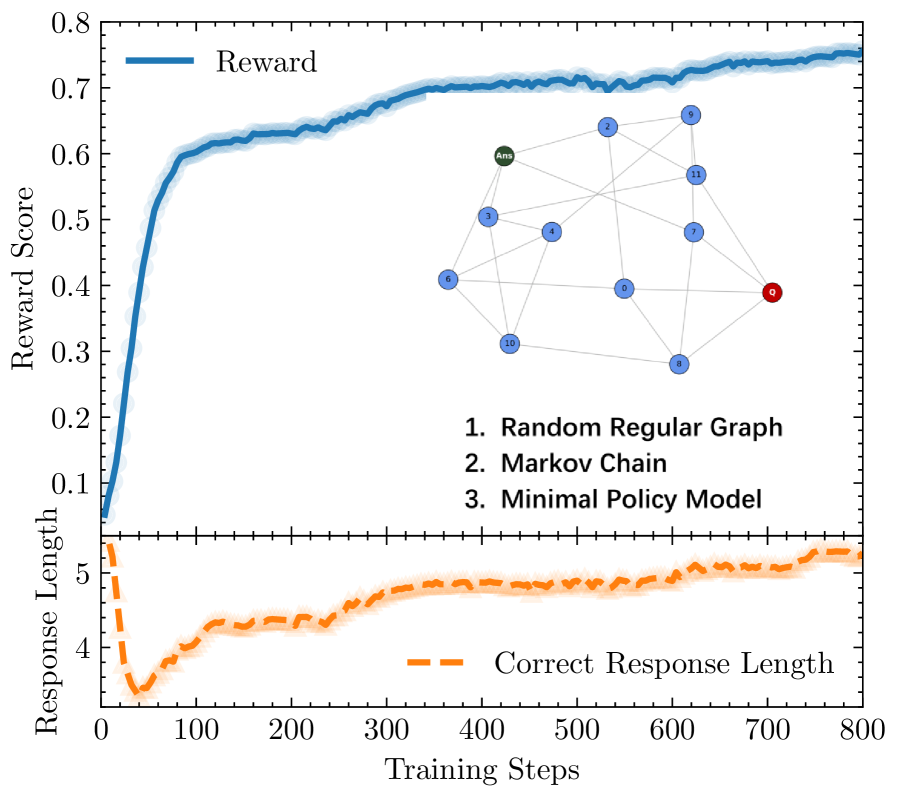
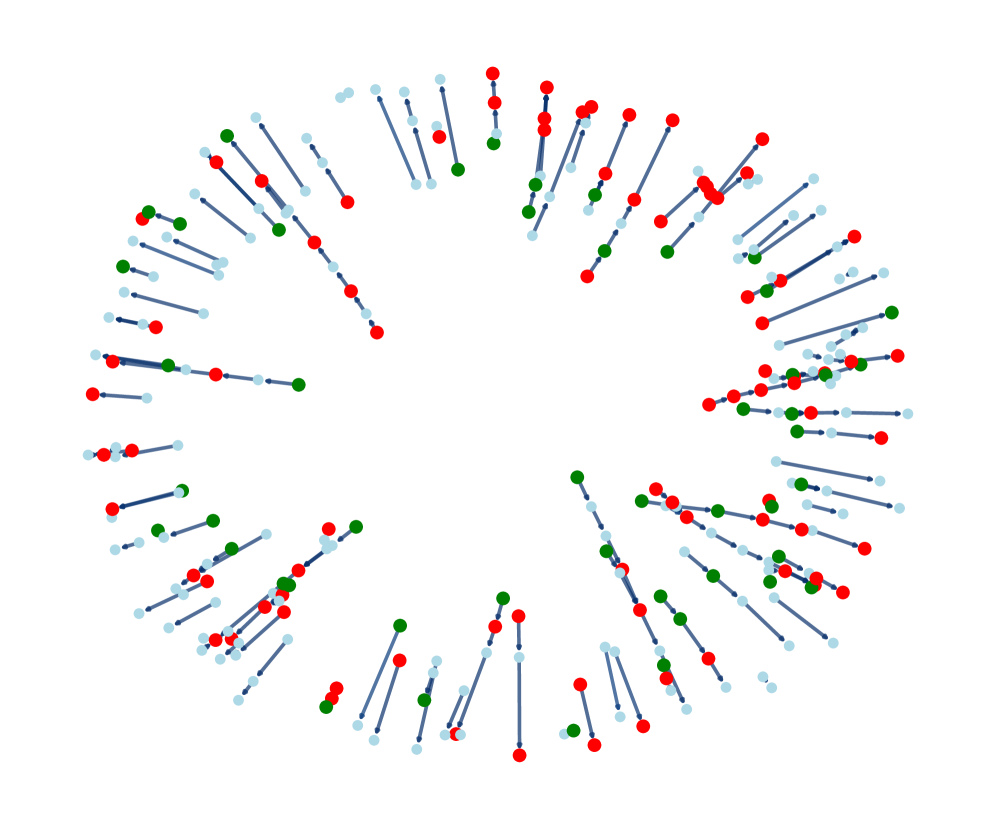
Visualization of the topological evolution of the 'Concept Web' during training
Evaluation Highlights
- Annealed-RLVR outperforms standard RLVR on in-distribution tasks (512 held-out problems) and out-of-distribution benchmarks (Minerva, AIME)
- Identifies a 'maximally frustrated state' where exploratory power peaks before collapsing, validating the timing for the proposed annealing intervention
- Demonstrates that catastrophic forgetting is topologically localized: resuming RLVR leads to rapid recovery by 're-soldering' broken connections rather than relearning from scratch
Breakthrough Assessment
9/10
Offers a unifying physical theory (sparse network topology) for multiple unexplained RLVR phenomena and successfully translates this theoretical insight into a practical algorithm (Annealed-RLVR) that improves SOTA reasoning benchmarks.