📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
RL-PLUS prevents LLM reasoning collapse by combining internal exploitation with external data using multiple importance sampling and an exploration-weighted advantage function that prioritizes correct but low-probability paths.
Core Problem
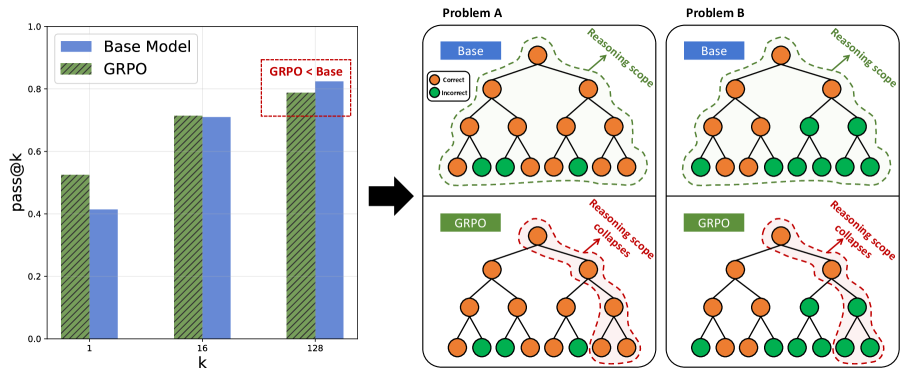
Standard RLVR (Reinforcement Learning with Verifiable Reward) improves average performance by refining known paths (inward exploitation) but fails to discover new solutions, causing the model's total potential capability (Pass@k) to shrink compared to the base model.
Why it matters:
- Current methods like GRPO improve Pass@1 but degrade Pass@128 (capability boundary collapse), effectively narrowing the model's problem-solving scope
- Sparse rewards in long reasoning chains make 'outward exploration' (finding completely new valid paths) extremely difficult for on-policy methods
- Reliance on inward exploitation limits the model to merely polishing existing knowledge rather than acquiring new reasoning abilities
Concrete Example:
In Figure 1(a), while an RLVR-trained model's Pass@1 exceeds the base model, its Pass@128 is substantially lower, indicating it has lost the breadth of potential solutions the base model originally possessed.
Key Novelty
Hybrid-policy Optimization with Exploration-Based Advantage
- Uses Multiple Importance Sampling (MIS) to stabilize learning from external data by treating samples as coming from a mixture of the old policy and external sources, preventing variance explosion
- Reshapes the RL reward using an 'Exploration-Based Advantage Function' that amplifies signals for correct answers the model currently assigns low probability to, explicitly incentivizing the learning of 'hard' knowledge
Architecture
Comparison of Pass@k curves between Base Model and RLVR-trained model
Evaluation Highlights
- +5.2 average points improvement over SFT+GRPO across six math reasoning benchmarks
- Up to 69.2% average relative improvement over GRPO across diverse model families
- Analysis of Pass@k curves confirms RL-PLUS maintains high potential (Pass@k) at large k, effectively resolving the capability boundary collapse issue seen in baselines
Breakthrough Assessment
8/10
Identifies and addresses a critical, subtle failure mode of current RLVR (capability collapse) with a theoretically grounded hybrid approach. Strong reported gains over standard GRPO.