📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Large Reasoning Models (LRMs)
SIREN prevents entropy collapse in large reasoning models by restricting entropy regularization to a semantic nucleus of actions and critical trajectory tokens, stabilizing exploration without causing global entropy explosions.
Core Problem
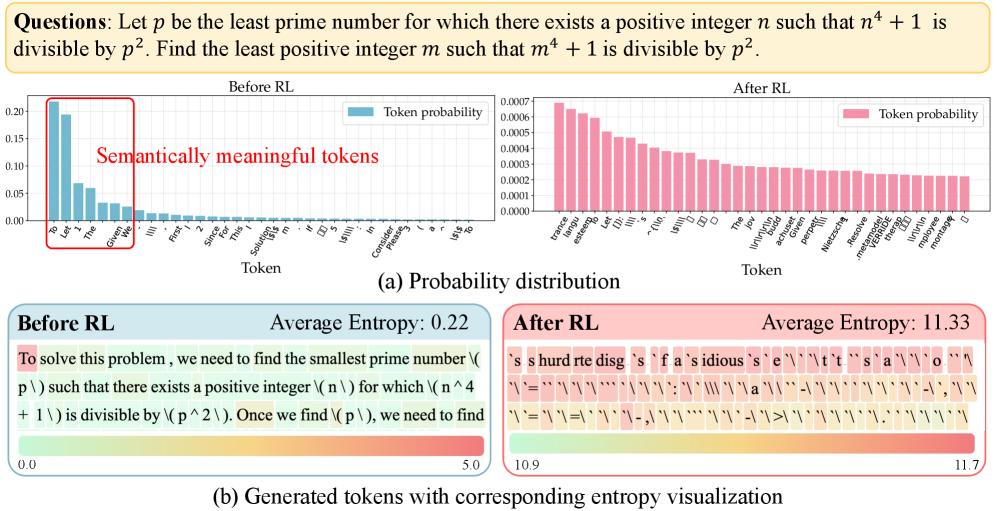
Naive entropy regularization in LRMs fails because the vast action space and long trajectories cause probability mass to diffuse indiscriminately, triggering global entropy explosions and incoherent outputs.
Why it matters:
- Current RLVR methods suffer from entropy collapse and premature convergence, leading to deterministic policies that stop exploring and produce repetitive, near-identical responses
- Naive regularization is hypersensitive: small coefficients yield no gain, while large ones cause the model to assign high probability to meaningless tokens, destroying reasoning coherence
Concrete Example:
In a math problem, a model with naive entropy regularization might output a uniform distribution of meaningless tokens instead of reasoning steps. The paper shows an entropy-exploded model where probability mass spreads across the entire vocabulary rather than focusing on valid mathematical operators or numbers.
Key Novelty
Selective Entropy Regularization (SIREN)
- constrains exploration to a 'policy nucleus' (top-p tokens) to prevent probability mass from leaking into the vast sea of meaningless tokens in the vocabulary
- targets regularization only on 'peak-entropy' tokens (critical logical connectors) along the trajectory, avoiding the cascade of uncertainty that ruins long chains of reasoning
- anchors the regularization target to the model's initial entropy level (self-anchored), dynamically adjusting strength to maintain diversity without manual tuning
Architecture
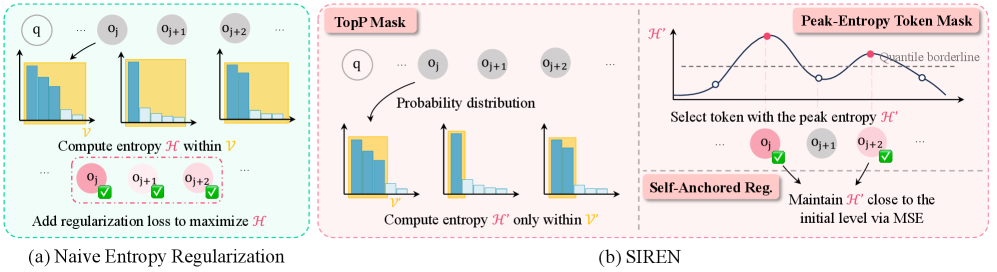
The overall framework of SIREN, illustrating the two-step masking process (Action-level and Trajectory-level) and the self-anchored regularization loop.
Evaluation Highlights
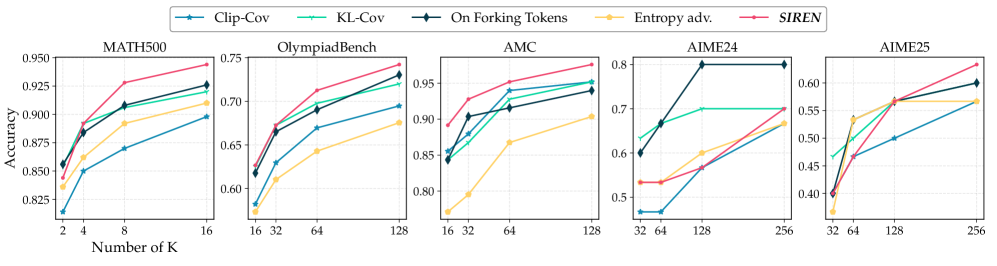
- +6.6 maj@32 improvement on AIME24 and AIME25 benchmarks using Qwen2.5-Math-7B compared to the best previous entropy-related baselines.
- Achieves 54.6 maj@k average across five math benchmarks, outperforming Dr.GRPO by +4.8 points.
- Consistent gains on smaller (Qwen2.5-Math-1.5B) and weaker (LLaMa3.1-8B) models, improving maj@k by +2.4 and +2.8 respectively.
Breakthrough Assessment
8/10
Identifies a fundamental failure mode of standard RL techniques in the LLM context (entropy explosion due to vocabulary size) and provides a logically grounded, effective fix that sets new state-of-the-art results.