📝 Paper Summary
Reinforcement Learning with Verifiable Reward (RLVR)
Long Chain-of-Thought (CoT) Reasoning
Reasoning Model Distillation
TFPI introduces a training stage where distilled reasoning models are optimized on input queries stripped of thinking tokens, reducing rollout costs while improving subsequent slow-thinking RL performance.
Core Problem
Training large reasoning models (LRMs) via RLVR requires processing extremely long Chain-of-Thought contexts during rollouts, leading to massive computational costs and potential performance degradation if contexts are shortened too aggressively.
Why it matters:
- Generating long Chains-of-Thought during RL training incurs substantial compute expenses (e.g., 8K H800 hours for a 4B model)
- Starting RL training with overly short contexts to save compute often causes irreversible drops in reasoning accuracy
- Current multistage training strategies are still computationally heavy and may not fully mitigate performance loss
Concrete Example:
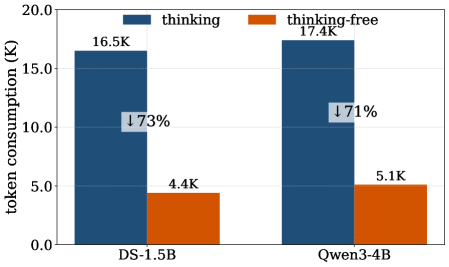
When training Qwen-3-4B using standard DAPO (a direct RL method) with a restricted 4K response length, accuracy on AIME25 drops significantly (reduces avg@32 by >40%). In contrast, applying the ThinkingFree operation allows the model to improve accuracy by ~2% under the same constraints.
Key Novelty
Thinking-Free Policy Initialization (TFPI)
- Initializes the RL policy by training on 'Thinking-Free' queries—inputs where the thinking content is explicitly discarded via a special token format (Thinking-Free operation)
- Forces the model to learn efficiently from short-context rollouts before transitioning to full long-CoT reasoning, acting as a bridge between distillation and standard RLVR
- Demonstrates that training in this thinking-free mode enhances the model's capability in the original slow-thinking mode while drastically reducing token consumption
Architecture
Conceptual comparison of TFPI versus standard Long-CoT RL and Multistage RL in terms of compute and performance.
Evaluation Highlights
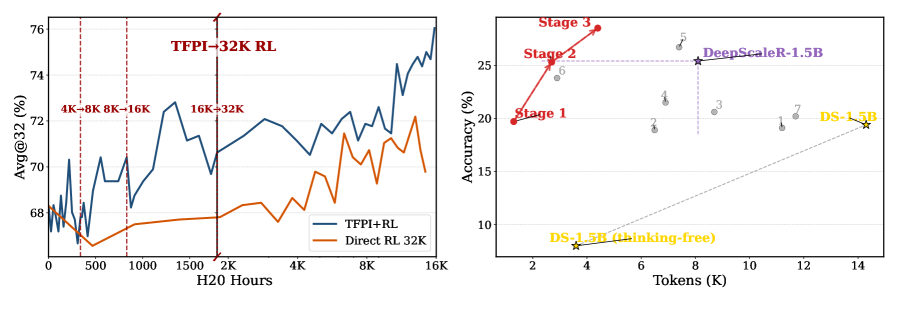
- Achieves 89.0% accuracy on AIME24 with a 4B model using TFPI only (no subsequent RL), consuming less than 4K H20 hours
- TFPI+RL boosts AIME25 accuracy for Qwen3-4B from 70.6% to 76.0% (+5.4%) compared to TFPI alone, surpassing Direct RL baselines under matched compute
- Reduces training compute significantly: TFPI+RL requires ~1.5K H800 GPU hours for a 4B model to outperform Polaris-4B (which uses ~8K hours)
Breakthrough Assessment
8/10
Offers a highly practical solution to the massive compute costs of training reasoning models. By validating that 'thinking-free' pre-training boosts 'slow-thinking' performance, it challenges the assumption that long-context training is strictly necessary at all stages.