📝 Paper Summary
Reinforcement Learning from Verifiable Rewards (RLVR)
Open-ended Text Generation
Reward Engineering
Rubicon extends reinforcement learning from verifiable domains (like math) to open-ended tasks by using thousands of structured, rule-based rubrics as reward signals, achieving gains in creativity and writing without sacrificing reasoning.
Core Problem
Current Reinforcement Learning from Verifiable Rewards (RLVR) relies on tasks with objectively checkable answers (like math or code), limiting its application to open-ended, subjective domains like creative writing or social interaction.
Why it matters:
- Strictly verifiable data is finite and covers a narrow slice of real-world utility, creating a hard ceiling on scalability for current reasoning models
- Optimizing for verifiable metrics alone often leads to 'AI-like', formulaic, or didactic responses in humanities tasks, lacking human-like nuance
- Prior methods struggle to provide scalable supervision for subjective tasks without relying solely on expensive and potentially noisy human preference labels
Concrete Example:
When asked 'When in your life have you felt the most alive?', a standard AI model gives a formulaic disclaimer ('I don't have feelings...'). Rubicon, trained with a 'Plain Narrative' rubric, generates a vivid, human-like story about a mountain trek, adhering to stylistic constraints like 'calm acceptance' and 'grounded realism'.
Key Novelty
Rubicon (Rubric Anchors for RL)
- Replace binary correctness checks with over 10,000 structured rubrics that define multi-dimensional criteria (e.g., tone, creativity, constraints), allowing 'verifiable-like' RL on subjective tasks
- Use a multi-stage RL training process to balance conflicting objectives: first optimizing for strict constraint following, then for open-ended creativity and empathy
- Deploy adaptive 'defense rubrics' derived from analysis of reward hacking behaviors (like sycophancy) to penalize the model when it tries to game the scoring system
Architecture
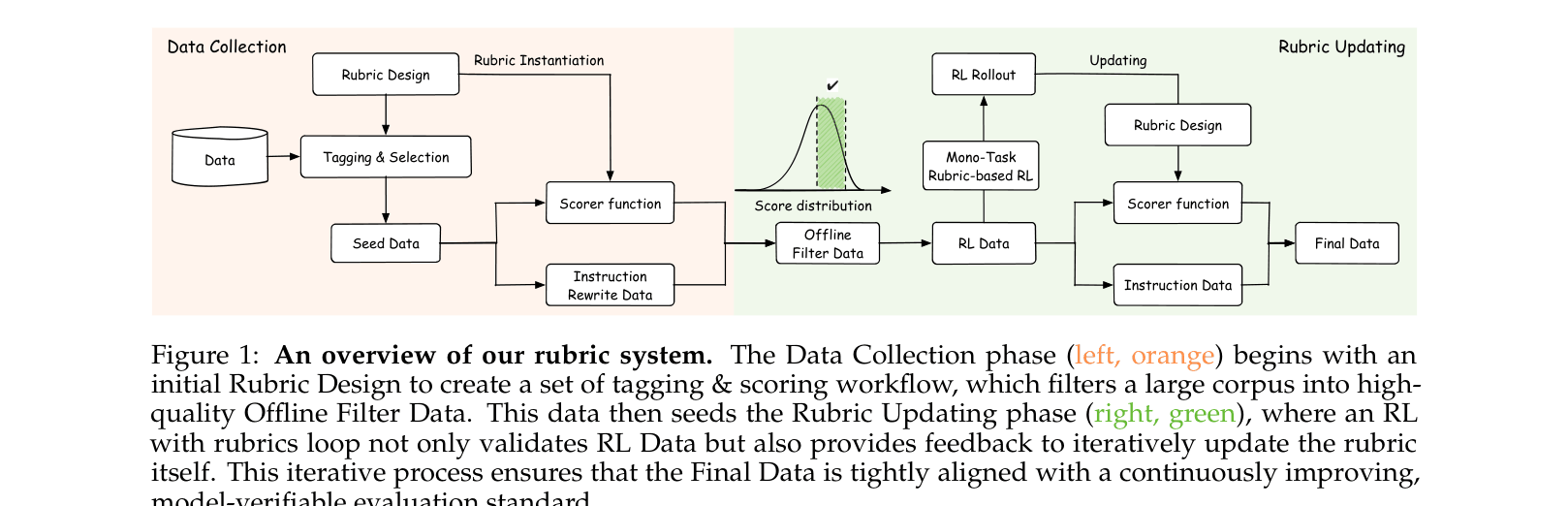
Overview of the Rubric System workflow, spanning data collection, rubric design, and the RL loop.
Evaluation Highlights
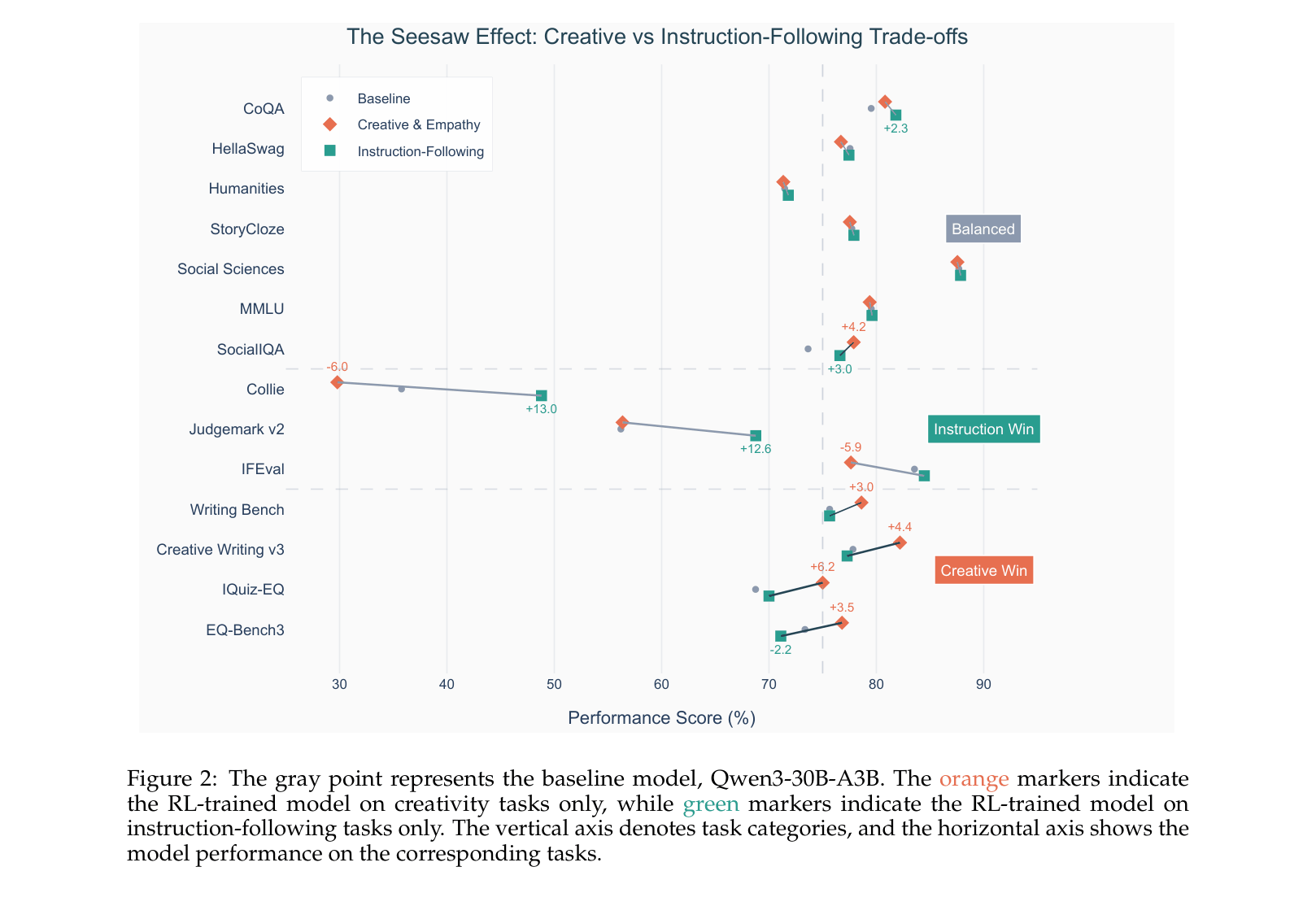
- +5.21% average improvement over the base Qwen3-30B-A3B model across 8 open-ended benchmarks, with notable gains on Judgemark V2 (+13.00%) and Writingbench (+4.46%)
- Outperforms the much larger DeepSeek-V3-671B by +2.41 percentage points on average across open-ended humanities tasks despite being a ~30B parameter model
- Maintains or improves reasoning capabilities, achieving +4.17% on AIME 2024 (math) while significantly enhancing creative writing performance
Breakthrough Assessment
8/10
Significantly expands the RLVR paradigm beyond math/code. Demonstrates that rule-based rubrics can effectively scale post-training for subjective tasks with high data efficiency.