📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Multimodal Large Language Models (MLLMs)
MSSR enables stable and compute-efficient reinforcement learning for multimodal models by using a single rollout per input with entropy-based advantage shaping to prevent optimization collapse.
Core Problem
Existing multimodal RLVR methods like GRPO require multiple rollouts per input for stability, which is computationally expensive and inefficient when rollouts yield identical rewards.
Why it matters:
- Group-based methods (e.g., GRPO) require repeated forward passes through large vision and language encoders, creating a substantial compute bottleneck.
- Naive single-rollout strategies from text-only RL fail in multimodal settings due to high variance from visual inputs, leading to entropy collapse and training instability.
- When all rollouts in a group have the same outcome (all correct/incorrect), relative advantage collapses to zero, wasting computation.
Concrete Example:
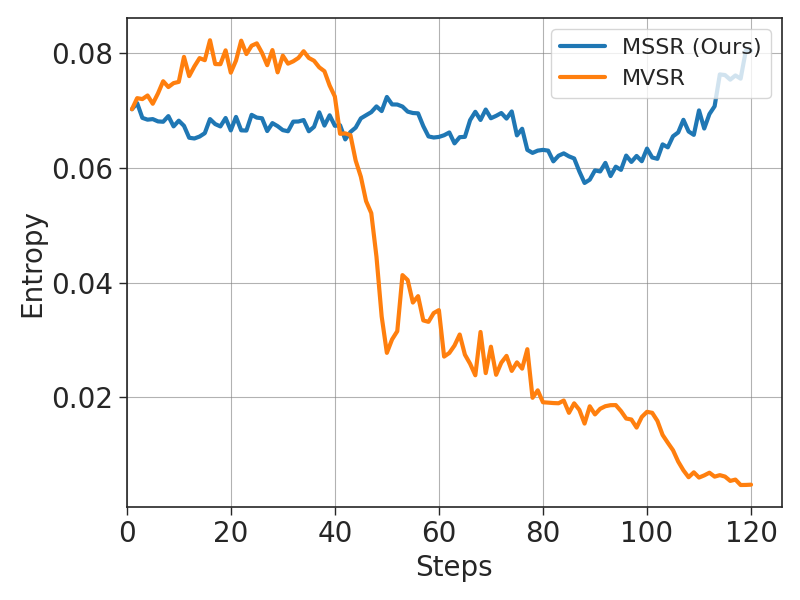
In a visual math problem, a single-rollout policy might produce a correct answer (reward=1) followed by an incorrect one (reward=0) for similar inputs due to visual noise. Without the group normalization used in GRPO, this high variance causes the policy entropy to plummet (entropy collapse), as seen in the MVSR baseline where accuracy degrades rapidly during training.
Key Novelty
Multimodal Stabilized Single-Rollout (MSSR)
- Generalizes text-only single-rollout RL to multimodal settings by modeling binary rewards as Bernoulli variables and estimating the baseline using a Beta distribution.
- Introduces entropy-based advantage shaping that adds a scaled entropy bonus to the advantage, softening penalties for high-uncertainty responses.
- Dynamically adapts the discount factor for the baseline estimate based on the KL divergence between consecutive policy updates to balance stability and adaptation.
Architecture
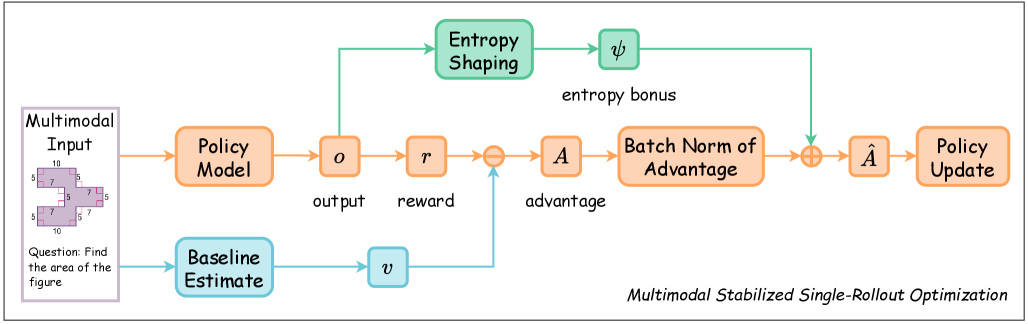
Overview of the MSSR framework compared to standard single-rollout (MVSR). It illustrates the flow from multimodal input to single rollout, reward calculation, Beta baseline estimation, and the critical addition of entropy-based advantage shaping.
Evaluation Highlights
- Achieves GRPO's final validation accuracy with 50% of the training steps (Figure 1), demonstrating superior compute efficiency.
- Outperforms the group-based GRPO baseline by an average of 2.1% (3B model) and 2.3% (7B model) across five multimodal reasoning benchmarks.
- Prevents the entropy collapse observed in naive single-rollout baselines (MVSR), maintaining exploration and training stability throughout optimization.
Breakthrough Assessment
8/10
Successfully transfers single-rollout efficiency to the challenging multimodal domain, resolving a key stability bottleneck (entropy collapse) that previously mandated expensive group-based methods.