📝 Paper Summary
Causal Analysis of LLMs
Reasoning Models (LRMs)
Chain-of-Thought (CoT) Reliability
By modeling reasoning as a causal graph, this study reveals that Reinforcement Learning with Verifiable Rewards (RLVR) enables models to develop genuine causal reasoning chains, whereas distillation merely mimics superficial correlations.
Core Problem
LLM reasoning (Chain-of-Thought) often lacks faithfulness, acting as a post-hoc explanation for a latent belief rather than a genuine derivation of the answer.
Why it matters:
- Superficial correlations lead to unfaithfulness, where correct reasoning steps can produce incorrect answers and vice-versa
- Without genuine causal structure, models fail to generalize and remain prone to bias and inconsistency
- The impact of new training paradigms like RLVR and Distillation on the underlying causal mechanism of reasoning was previously unexplored
Concrete Example:
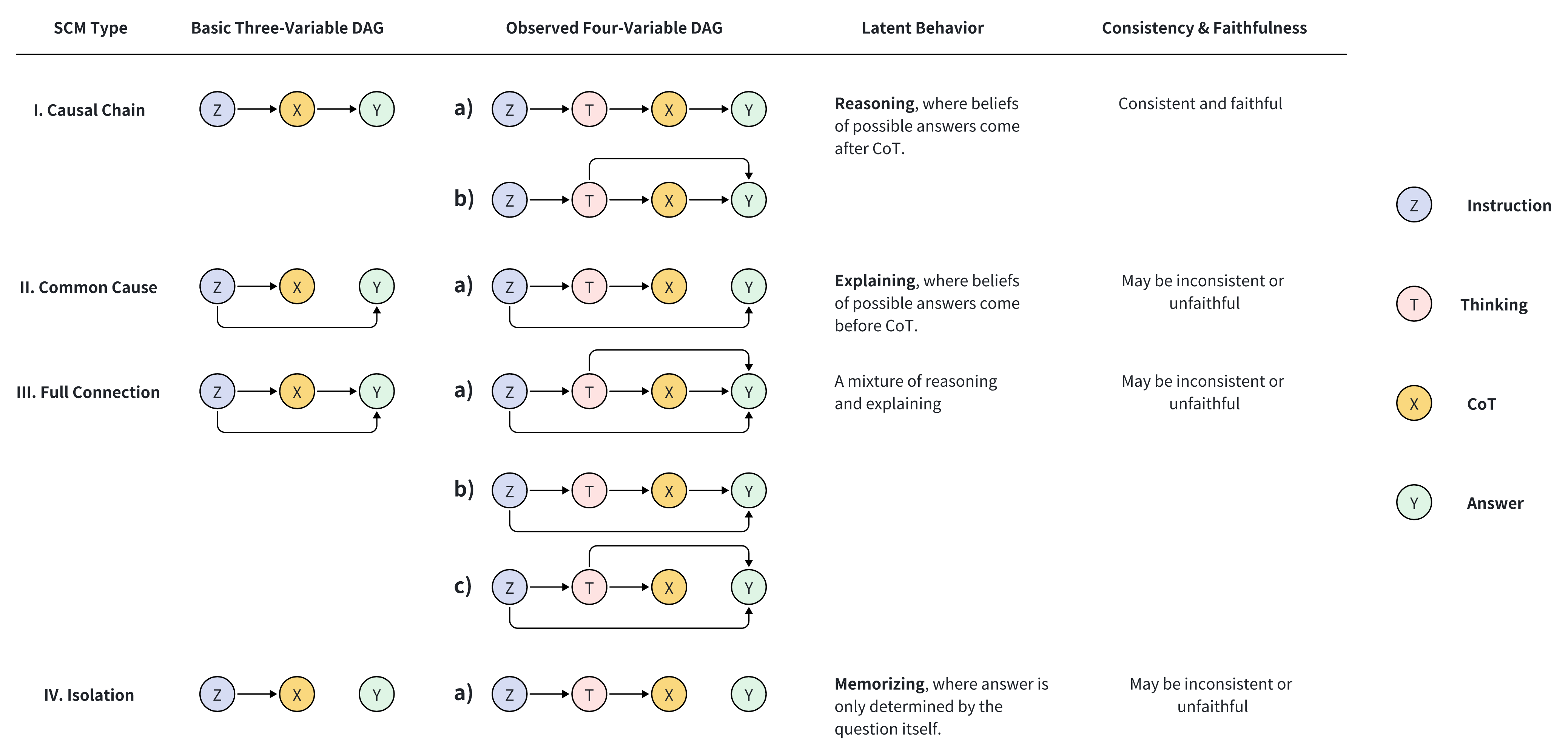
In a 'Common Cause' (Type II) failure, a model might decide the answer is '42' based on the instruction context alone (the latent belief) and then generate a reasoning chain just to justify that number, rather than calculating '42' through the reasoning steps. If the reasoning is perturbed, the answer '42' remains unchanged, indicating the reasoning did not cause the answer.
Key Novelty
Causal Analysis Framework for Large Reasoning Models (LRMs)
- Models the reasoning process using Structural Causal Models (SCMs) with four variables: Instruction, Thinking (internal CoT), Reasoning Steps (explicit CoT), and Answer
- Uses interventional experiments (Average Treatment Effect) to determine which variable actually dictates the answer, distinguishing between genuine reasoning (Causal Chain) and mere explanation (Common Cause)
Architecture
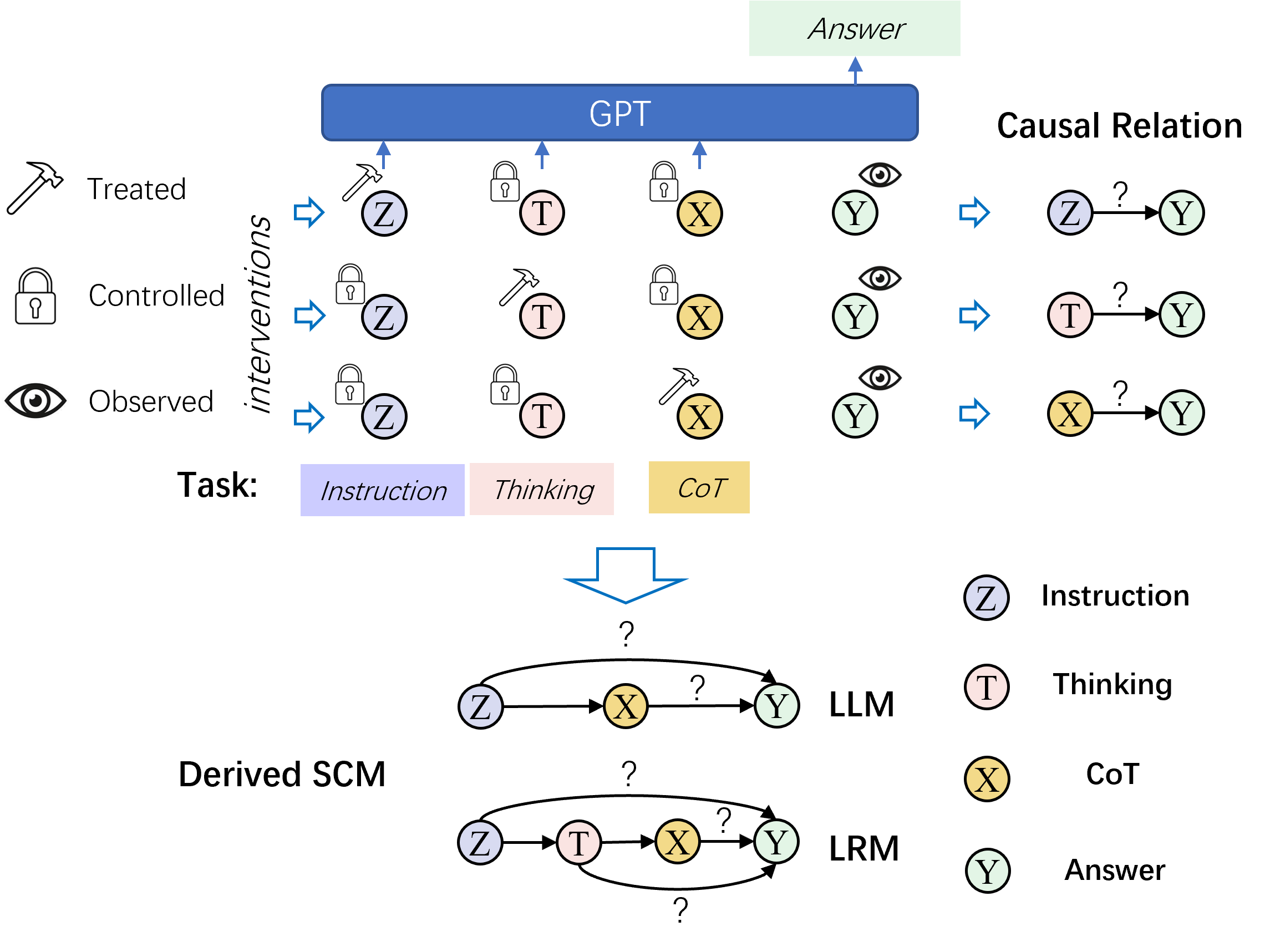
The Causal Analysis Framework showing the variables and potential causal links in the reasoning process.
Breakthrough Assessment
8/10
Provides a fundamental theoretical framework for understanding *why* RLVR works better than distillation for reasoning, shifting the focus from accuracy metrics to causal structural integrity.