📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Reinforcement Learning with Verifiable Rewards (RLVR)
Affective Computing
R1-Omni applies Reinforcement Learning with Verifiable Rewards (RLVR) to a video-audio multimodal model, significantly improving emotion recognition accuracy, reasoning transparency, and out-of-distribution generalization.
Core Problem
Existing multimodal large language models often lack robust reasoning capabilities for emotion recognition and struggle to generalize to out-of-distribution video data, as standard supervised fine-tuning (SFT) provides limited supervision for the reasoning process itself.
Why it matters:
- Emotion recognition requires integrating complex, dynamic cues from both visual (facial expressions) and audio (tone, pitch) modalities, which simple classification models often miss.
- Current MLLMs trained via SFT often hallucinate reasoning or fail to effectively utilize all modalities, leading to poor performance on unseen data distributions.
- RLVR has shown success in math and coding but has not yet been explored for video-based omni-multimodal tasks involving subjective reasoning like emotion.
Concrete Example:
In a video where a character smiles but uses a sarcastic tone, a standard SFT model might focus only on the visual smile and predict 'happy'. R1-Omni, trained to explicate its reasoning, analyzes the conflict between the smile and the tone to correctly reason through the sarcasm and predict the true underlying emotion.
Key Novelty
RLVR for Video Omni-Multimodal Emotion Recognition
- Extends the 'DeepSeek R1' training paradigm (Reinforcement Learning with Verifiable Rewards) to multimodal video-audio data, a first for this domain.
- Uses a binary ground-truth reward for emotion classification accuracy combined with a format reward to enforce structured 'thinking' and 'answer' outputs.
- Employ Group Relative Policy Optimization (GRPO) to optimize the policy without a separate critic model, evaluating groups of responses to stabilize training.
Architecture

Conceptual flow of the RLVR training process applied to the Omni model.
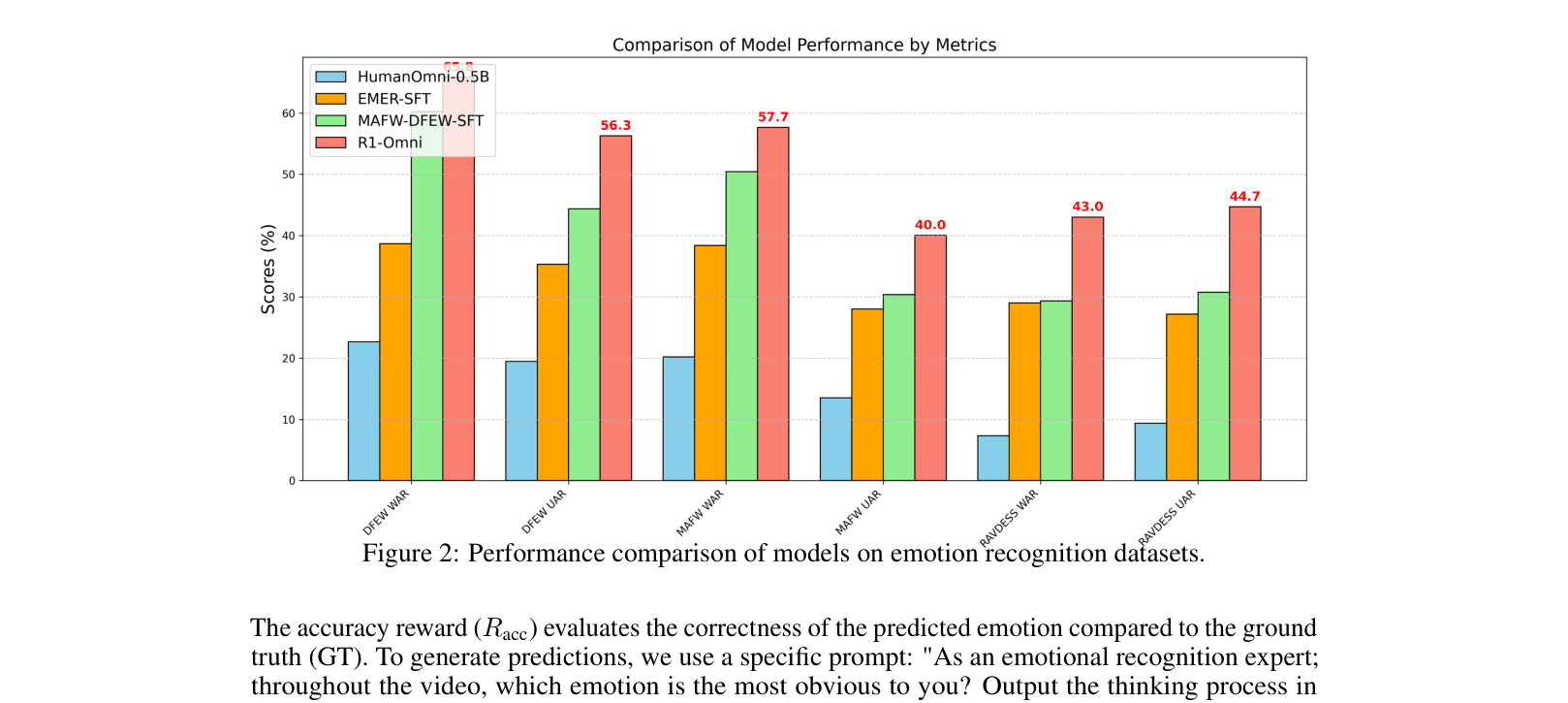
Evaluation Highlights
- +15.6% UAR (Unweighted Average Recall) improvement on the DFEW dataset compared to the supervised fine-tuning (SFT) baseline.
- +13.67% UAR improvement on the out-of-distribution RAVDESS dataset compared to SFT, demonstrating strong generalization.
- Consistently outperforms the base HumanOmni-0.5B model and SFT variants across both in-distribution (MAFW, DFEW) and out-of-distribution (RAVDESS) benchmarks.
Breakthrough Assessment
8/10
First successful application of the R1/RLVR paradigm to video-audio multimodal tasks. Significant performance jumps over SFT (+13-15%) validate the approach, though limited to emotion recognition so far.