📝 Paper Summary
Mathematical Reasoning
Large Language Model Fine-tuning
Reinforcement Learning from Verifiable Rewards (RLVR)
OXA fine-tunes language models on offline reasoning trajectories by promoting low-confidence correct answers and suppressing high-confidence errors, creating a high-entropy initialization that enhances subsequent reinforcement learning for math reasoning.
Core Problem
Standard Supervised Fine-Tuning (SFT) initializes models with low policy entropy, causing them to memorize specific paths and prematurely converge during subsequent Reinforcement Learning (RL), limiting exploration.
Why it matters:
- SFT is the critical starting point for RLVR; a poor initialization constrains the model's ability to discover new reasoning paths later
- Existing methods focus on fixing exploration *during* RLVR, neglecting the potential to bake exploration capabilities into the SFT stage itself
- RLVR excels at optimizing known paths but struggles to expand the fundamental reasoning space, which SFT is better suited to do
Concrete Example:
When trained to convergence via standard SFT, a model's entropy collapses, making the predictive distribution sharp (peaked). Consequently, during RLVR, the model repeatedly samples the same high-probability reasoning path for a math problem, failing to explore alternative valid derivations that might lead to better generalization.
Key Novelty
Offline eXploration-Aware (OXA) Fine-Tuning
- Counteracts entropy collapse by flattening the predictive distribution: it boosts the probability of valid reasoning paths that the model is currently unsure about (low-confidence truths)
- Simultaneously reduces the probability of incorrect paths that the model is overly sure about (high-confidence errors), redistributing mass to potentially correct alternatives
- Uses a Gaussian-guided sampling algorithm to select training data based on perplexity, ensuring a mix of difficulty levels rather than just the easiest or hardest samples
Architecture
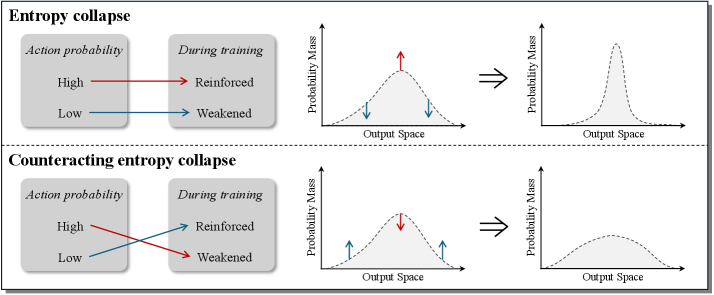
Conceptual illustration of entropy dynamics. Upper: Standard SFT leads to entropy collapse (sharp distribution). Lower: OXA maintains high entropy by promoting probability at troughs (low-confidence truths) and suppressing peaks (high-confidence errors).
Evaluation Highlights
- Achieves average gain of +6.6 Pass@1 and +5.5 Pass@k points compared to conventional SFT on Qwen2.5-1.5B-Math across 6 benchmarks
- Maintains significantly higher initial policy entropy compared to standard SFT, which persists throughout subsequent RLVR training
- Gains are additive when combined with RLVR-enhancement methods, proving orthogonality to existing RL techniques
Breakthrough Assessment
8/10
Offers a distinct perspective by shifting the exploration problem from the RL stage to the SFT initialization stage. The consistent, significant gains across multiple models and benchmarks demonstrate strong practical value.