📝 Paper Summary
LLM Reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
Knowledge Distillation
RLVR improves accuracy by reinforcing easy problems at the expense of hard ones without expanding capability, whereas distillation can expand capability only when it introduces new knowledge.
Core Problem
While RLVR improves the probability of generating correct answers (accuracy), it often fails to enable models to solve previously unsolvable problems (capability), and the mechanisms behind this limitation are poorly understood.
Why it matters:
- Understanding whether methods like RLVR actually teach new skills or just amplify existing ones is critical for developing Artificial General Intelligence (AGI)
- Current reasoning models often plateau in capability despite expensive RL training cycles
- Distinguishing between 'reasoning patterns' and 'knowledge' helps optimize training recipes (e.g., when to use distillation vs. RL)
Concrete Example:
A base model might solve a hard math problem 1 out of 256 times. After RLVR training, instead of improving, the model might solve it 0 times because the training algorithm (GRPO) ignores batches where all responses are wrong, causing the model to optimize only for easier questions it can already solve frequently.
Key Novelty
The 'Sacrificing-Difficult-Problems' Phenomenon in RLVR
- Demonstrates that RLVR improves overall accuracy by boosting performance on easy questions while actually degrading performance on the hardest questions (those with near-zero initial success probability)
- Attributes this to policy gradient algorithms like GRPO, which update parameters based only on questions where at least one correct response is generated, effectively ignoring difficult problems
- Disentangles 'reasoning patterns' from 'knowledge' in distillation, showing that distilling reasoning patterns alone (like RLVR) improves accuracy, while distilling from a teacher with more knowledge expands capability
Architecture
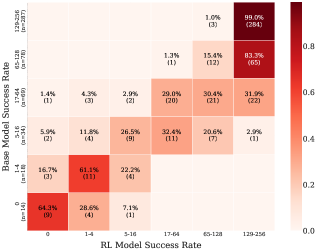
A transition matrix showing how questions move between success-rate bins before and after RLVR training
Evaluation Highlights
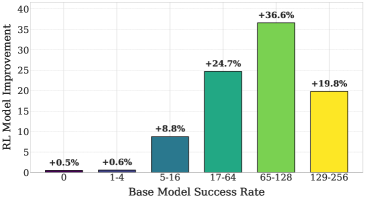
- RLVR increases test accuracy of Qwen2.5-1.5B-Math from 62.6% to 74.8% on MATH 500, but fails to improve capability (pass@256), which often remains stagnant.
- In difficulty bin analysis, questions with low initial success probability (1-4 successes out of 256) stagnate or regress: 16.7% of such questions drop to 0 successes after RLVR training.
- Distilling the RLVR model's responses into the base model achieves 74.2% accuracy (matching the RLVR model itself), whereas self-distillation (base model on itself) only reaches 63.4%.
Breakthrough Assessment
7/10
Provides a crucial diagnostic insight into why RLVR fails to generalize to harder problems. While it doesn't propose a new SOTA method, the analysis of the 'sacrificing' mechanism is a valuable contribution to the science of LLM training.