📊 Experiments & Results
Evaluation Setup
Mathematical reasoning and Text2SQL generation under various noise conditions
Benchmarks:
- MATH-500 (Mathematical Reasoning)
- AIME (Mathematical Reasoning (Competition Level))
- BIRD (Text-to-SQL)
Metrics:
- Accuracy (Pass@1)
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results on mathematical reasoning showing the impact of truly noisy data vs. clean data. | ||||
| MATH-500 | Accuracy | Not reported in the paper | Not reported in the paper | -9.0% |
| BIRD (Text2SQL) | Accuracy | Not reported in the paper | Not reported in the paper | -12.0% |
| MATH-500 | Accuracy | Not reported in the paper | Not reported in the paper | -3.0% |
Experiment Figures
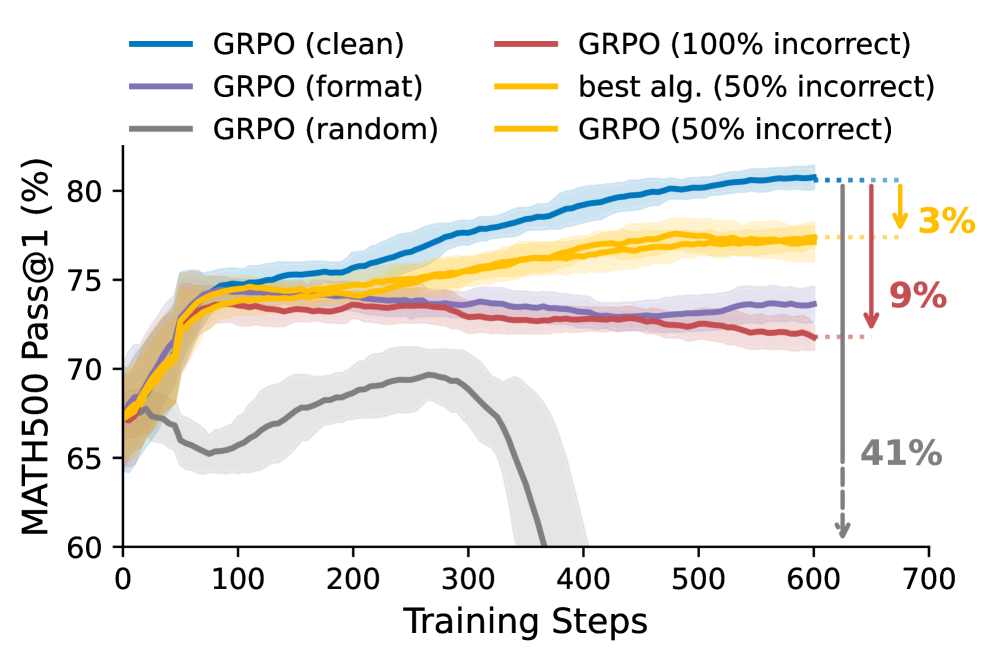
Comparison of model performance on MATH-500 when trained on Clean, Contaminated Noisy (prior work), and Truly Noisy data
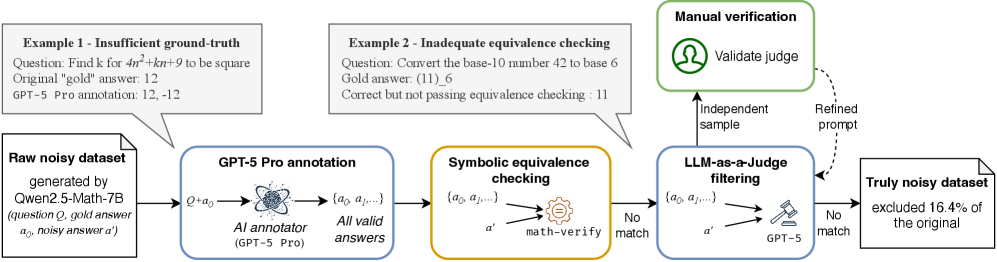
Examples of contamination in prior noisy datasets
Main Takeaways
- Prior 'noisy' datasets were contaminated: >16% of 'incorrect' labels were actually correct, inflating robustness claims.
- True noise is destructive: When trained on rigorously incorrect data, models perform 8-10% worse than clean baselines, similar to models trained only on format rewards.
- Algorithms cannot fix bad data: Advanced methods like bias mitigation and adaptive clipping fail to compensate for true annotation noise.
- Real-world relevance: Findings extend to Text2SQL (BIRD), where natural human errors cause significant performance drops (up to 12%), proving this is not just a synthetic artifact.