📊 Experiments & Results
Evaluation Setup
Mathematical reasoning tasks with exact match evaluation
Benchmarks:
- AIME 2024 / 2025 (Competition Math)
- AMC (Competition Math)
- MATH-500 (Competition Math)
- Minerva (Scientific Reasoning)
- OlympiadBench (Olympiad Math)
- ARC-c (Out-of-Distribution Reasoning (ARC Challenge))
- GPQA (Out-of-Distribution Reasoning (Graduate Science))
- MMLU-Pro (Out-of-Distribution Reasoning (Professional Exams))
Metrics:
- Pass@1
- Avg@32 (for AIME/AMC)
- Statistical methodology: p < 0.05 significance testing reported
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| LUFFY consistently outperforms baselines on in-distribution math benchmarks, establishing a new SOTA for RLVR on Qwen2.5-Math-7B. | ||||
| Average (6 Math Benchmarks) | Score | 45.5 | 50.1 | +4.6 |
| Average (6 Math Benchmarks) | Score | 43.7 | 50.1 | +6.4 |
| AIME 2025 | Avg@32 | 15.3 | 23.1 | +7.8 |
| LUFFY shows strong generalization to out-of-distribution (OOD) tasks where on-policy methods struggle. | ||||
| Average (ARC-c, GPQA, MMLU-Pro) | Score | 51.6 | 57.8 | +6.2 |
| LUFFY enables training of smaller/weaker models where standard RL fails. | ||||
| Average (6 Math Benchmarks) | Score | 30.0 | 38.0 | +8.0 |
Experiment Figures
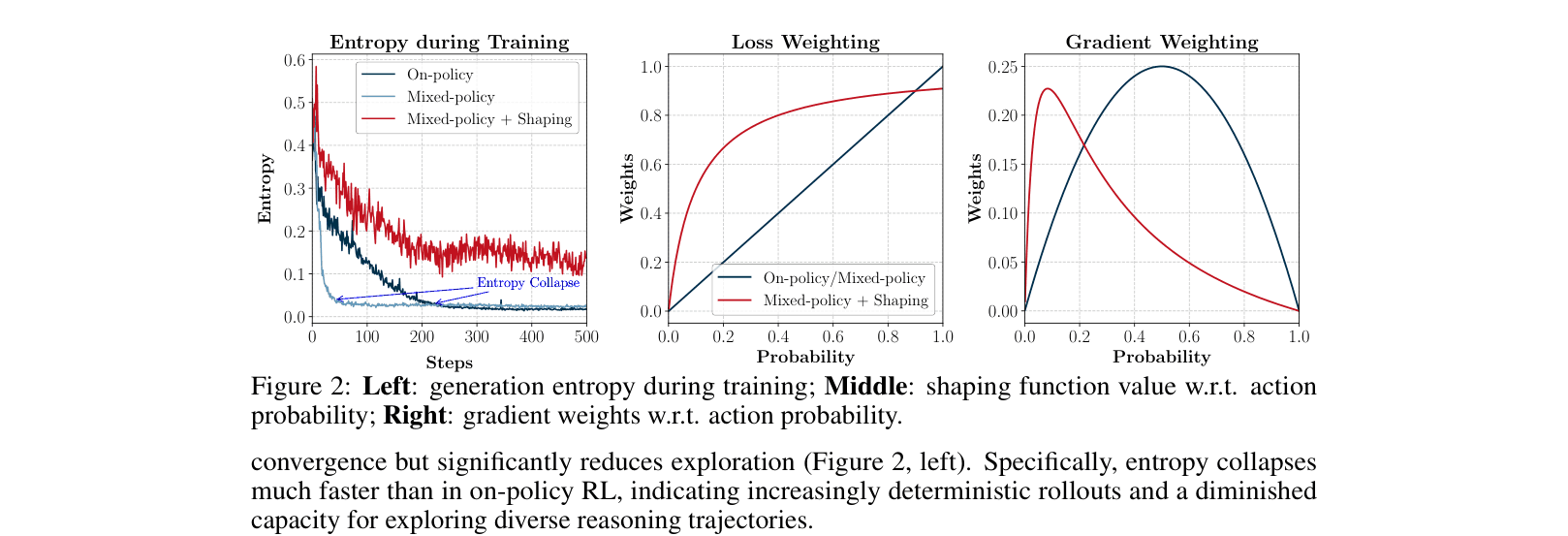
Entropy analysis during training comparing On-policy, Mixed-policy, and LUFFY (Mixed-policy + Shaping).
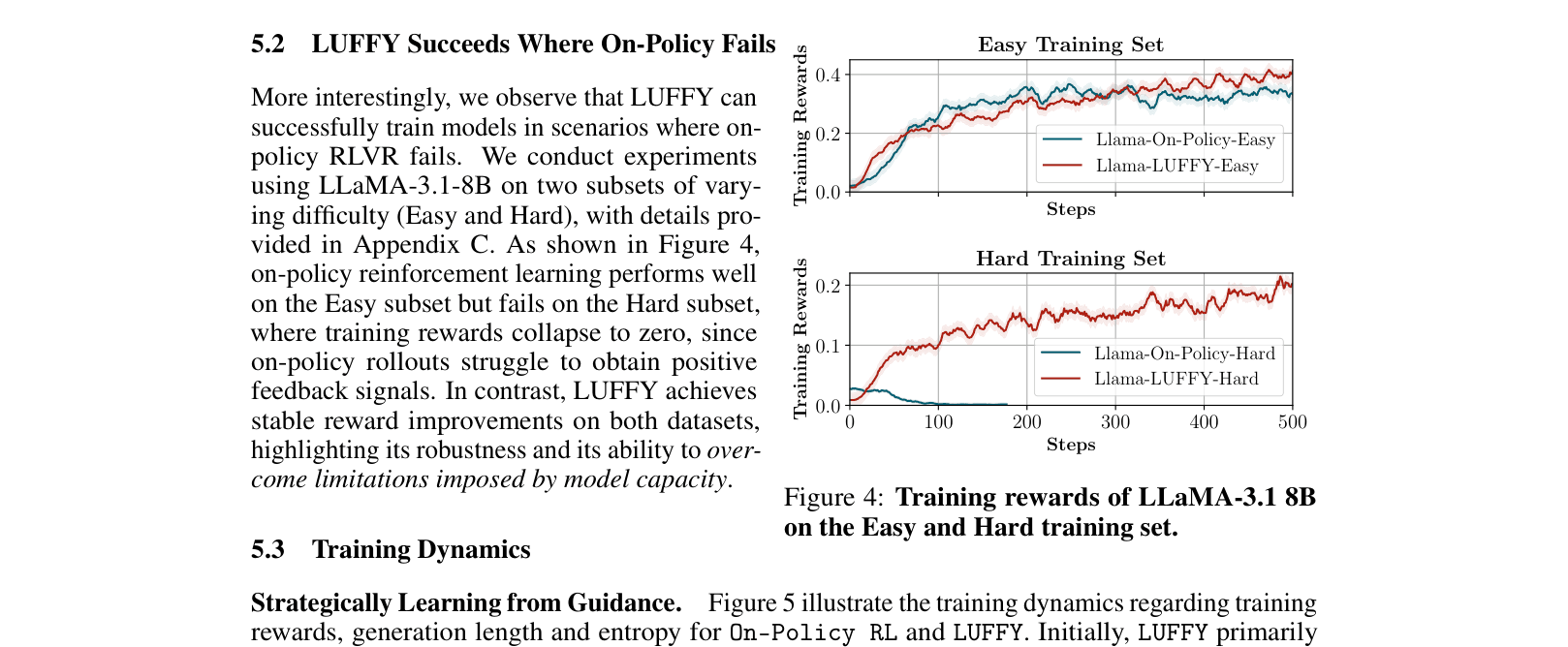
Training rewards for Llama-3.1-8B on Easy vs. Hard datasets.
Main Takeaways
- Off-policy guidance is critical for overcoming the 'cold start' problem in RLVR, enabling weak models (Llama-3.1-8B) to learn where on-policy methods completely fail.
- Policy shaping prevents entropy collapse: without it, mixed-policy training leads to rigid imitation and loss of exploration (Fig 2).
- LUFFY achieves a better balance of imitation and exploration than sequential SFT+RL, as evidenced by superior performance with significantly less compute (59% of SFT+RL GPU hours).
- The method generalizes well to out-of-distribution tasks (GPQA, ARC-c), suggesting the model learns general reasoning patterns rather than just memorizing math solutions.