📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Compositional Generalization
Chain of Thought (CoT) Reasoning
RLVR can efficiently learn correct compositional reasoning from outcome feedback only when correct intermediate steps provide a statistical "task-advantage" in verification probability compared to incorrect steps.
Core Problem
RLVR provides global feedback (pass/fail) for a sequence of decisions, making it ambiguous which intermediate steps were responsible for success or failure.
Why it matters:
- Models may converge to suboptimal "shortcuts" or fail to learn correct reasoning chains even with infinite data if the feedback signal doesn't propagate correctly
- It is unknown why RLVR succeeds on some reasoning tasks but fails or degrades performance on others
- Understanding the theoretical limits of outcome-based supervision is critical as supervision of intermediate steps is often costly or unavailable
Concrete Example:
In a multi-step math problem, a model might use an incorrect formula but still arrive at the correct final answer due to luck or cancellation of errors. If this 'lucky' path passes the verifier as often as the rigorous path (low task-advantage), RLVR will not distinguish between them, potentially reinforcing the flaw.
Key Novelty
Task-Advantage Ratio
- Introduces a theoretical quantity called the 'task-advantage ratio': the probability of verification success when a specific task is selected versus when it is not
- Proves that the gradient update direction for any intermediate step is strictly governed by this ratio
- Establishes that efficient learning requires this ratio to be favorable; otherwise, the model faces exponential complexity or suboptimal convergence
Architecture
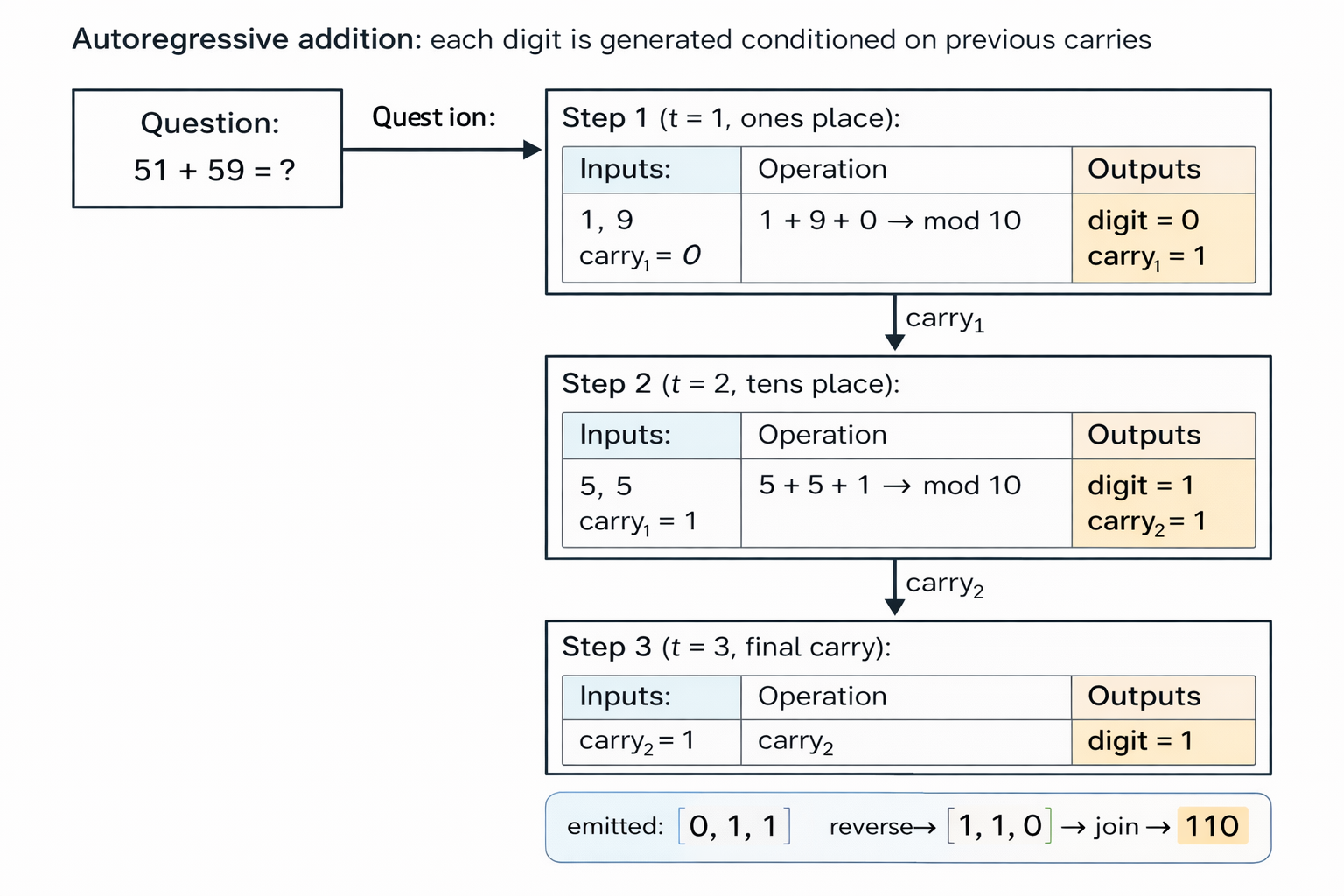
Conceptual illustration of decomposing a complex problem (adding two large numbers) into a sequence of simpler autoregressive tasks.
Evaluation Highlights
- Proved that when the task-advantage ratio condition holds, RLVR converges to the correct composition in O(S²) iterations (quadratic in Chain of Thought length)
- Demonstrated theoretically that without structural advantage, RLVR may converge to suboptimal compositions even without representational barriers
- Identified that poor base model quality can provably prevent learning by lowering the task-advantage ratio, explaining why weak models fail to improve with RLVR
Breakthrough Assessment
8/10
Provides a fundamental theoretical grounding for RLVR, explaining both its successes and failures through a single structural property. While theoretical, it offers essential insights into the limits of outcome-supervised reasoning.