📊 Experiments & Results
Evaluation Setup
Medical Visual Question Answering (VQA) across diverse modalities (Radiology, Pathology, etc.)
Benchmarks:
- VQA-RAD (Radiology VQA)
- SLAKE (Bilingual Medical VQA)
- PathVQA (Pathology VQA)
- PMC-VQA (Large-scale Medical VQA)
- MMMU (Medical subset) (Multi-discipline Understanding)
Metrics:
- Accuracy (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MedEyes consistently outperforms both general VLMs and specialized medical models across all 5 benchmarks. | ||||
| VQA-RAD | Accuracy | 56.4 | 70.7 | +14.3 |
| SLAKE | Accuracy | 62.7 | 79.1 | +16.4 |
| PathVQA | Accuracy | 56.8 | 64.8 | +8.0 |
| Average | Accuracy | 57.4 | 65.9 | +8.5 |
| Average | Accuracy | 46.1 | 65.9 | +19.8 |
Experiment Figures
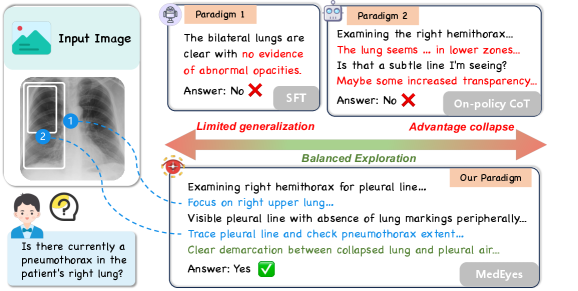
Comparison of reasoning paths between SFT, standard CoT, and MedEyes on a Pneumothorax case.
Main Takeaways
- MedEyes enables initially weak models to achieve state-of-the-art performance, surpassing much larger models like GPT-4o on specific benchmarks (e.g., VQA-RAD).
- The dual-stream GRPO effectively mitigates 'advantage collapse' where models typically ignore visual evidence in favor of language priors.
- The 'Scanning-Drilling' exploration strategy aligns well with human clinical diagnosis, improving both interpretability and accuracy.