📊 Experiments & Results
Evaluation Setup
RL post-training on mathematical reasoning and agentic tasks
Benchmarks:
- DAPO-Math-18K (Mathematical Reasoning)
- ALFWorld (Agentic text-based game)
- SWE-bench (Software Engineering (Agentic))
Metrics:
- Throughput (samples/second)
- Pass@1 (Accuracy)
- Training time per step
- GPU Utilization
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Throughput and speedup experiments demonstrate significant gains over synchronous baselines, especially as GPU count increases or model reasoning depth (sequence length) grows. | ||||
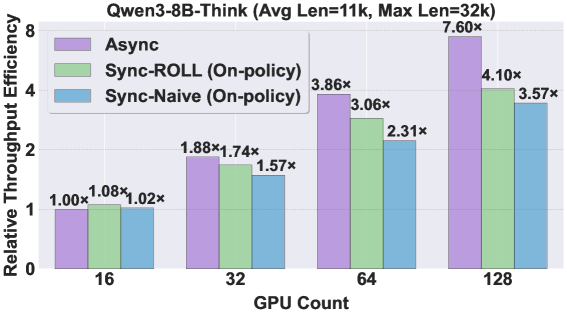
| DAPO-Math-18K (Qwen3-Think) | Speedup vs Sync-Naive | 1.0 | 7.6 | +6.6 |
| DAPO-Math-18K (Qwen3-Think) | Throughput vs Sync-Naive | 1.0 | 2.13 | +1.13 |
| DAPO-Math-18K (Qwen3-Base) | Throughput vs Sync-Naive | 1.0 | 2.24 | +1.24 |
| ALFWorld | Speedup | 1.0 | 2.72 | +1.72 |
| SWE-bench | Speedup | 1.0 | 1.81 | +0.81 |
Experiment Figures
Throughput (samples/sec) vs Number of GPUs for Sync-Naive, Sync-ROLL, and Async methods.
(a) Efficiency under varying Train-Inference resource splits; (b) Training time per step vs rollout batch size.
Main Takeaways
- Asynchronous training is inherently more efficient than synchronous training for RLVR because it saturates the rollout stage and prevents training stalls due to long-tail generation.
- A small Async Ratio (e.g., 2) is sufficient to realize near-maximal acceleration while preserving sample freshness; increasing it further yields diminishing returns.
- Existing off-policy algorithms (Weighted TOPR, GRPO with clipping) effectively compensate for stale samples, achieving Pass@1 accuracy comparable to synchronous training.
- Resource allocation between training and inference GPUs is critical; a balanced split (e.g., 24Train/16Infer) often outperforms splits that heavily favor one stage.