📝 Paper Summary
Agentic RAG pipeline
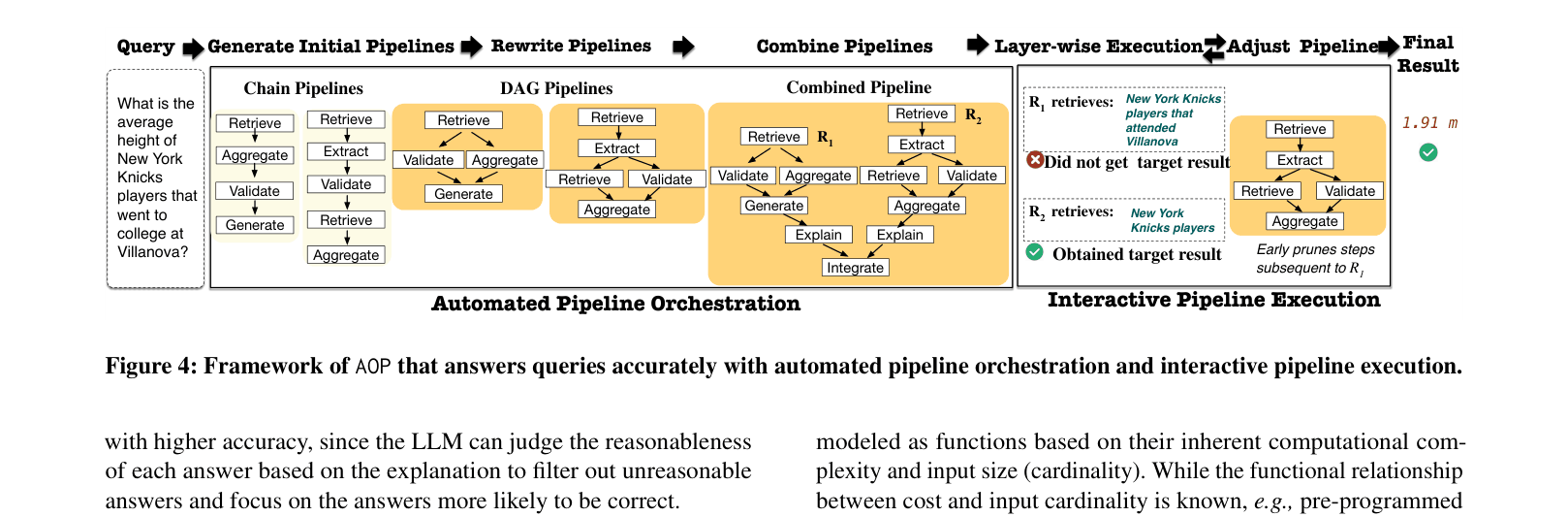
AOP is a framework that automates the orchestration and optimization of LLM pipelines for complex queries by assembling predefined semantic operators into interactive, self-reflecting execution workflows.
Core Problem
Current data lakes and static LLM pipelines (like basic RAG) struggle with complex queries requiring multi-hop retrieval, logical reasoning, and analytics across heterogeneous data because they lack dynamic planning and interactive adjustment.
Why it matters:
- Manual pipeline orchestration is brittle, costly, and requires significant human expertise to design effective workflows
- Static pipelines cannot adapt to intermediate failures (e.g., retrieving irrelevant documents), leading to error propagation and incorrect final answers
- Existing systems fail to effectively link and analyze heterogeneous data types (structured tables, unstructured documents) simultaneously for complex reasoning
Concrete Example:
For the query 'Who are the members of the men's team table tennis champion team at the 2024 Olympic Games?', a standard RAG might fail because it requires multi-hop retrieval: first finding the winning team from news (unstructured), then looking up the roster in a table (structured). AOP handles this by linking the 'champion team' concept to a specific roster lookup.
Key Novelty
Automated Semantic Operator Orchestration
- Decomposes complex queries into chains of standard 'semantic operators' (e.g., Semantic Filter, Retrieve, Aggregate) rather than bespoke code
- Uses an LLM-based planner to generate initial operator chains, rewrites them into Directed Acyclic Graphs (DAGs) for parallelism, and optimizes them using a cost model
- Executes pipelines interactively, allowing the system to inspect intermediate results and dynamically adjust the plan (e.g., pruning paths if retrieval fails)
Architecture

The AOP architecture, illustrating the flow from Query Interface to Planner, Optimizer, Executor, and finally the Answer.
Evaluation Highlights
- +45% accuracy improvement on a challenging subset of the CRAG benchmark compared to directly asking the LLM
- Reduces execution latency by utilizing parallel execution of independent operators within DAG-structured pipelines
- Demonstrates effective handling of heterogeneous data by linking structured tables and unstructured text via semantic operators
Breakthrough Assessment
8/10
Significantly advances Agentic RAG by formalizing 'semantic operators' similar to database algebra, enabling systematic optimization and interactive execution for complex, multi-modal queries.