📝 Paper Summary
Mathematical Reasoning
RLHF / RLVR (Reinforcement Learning with Verifiable Rewards)
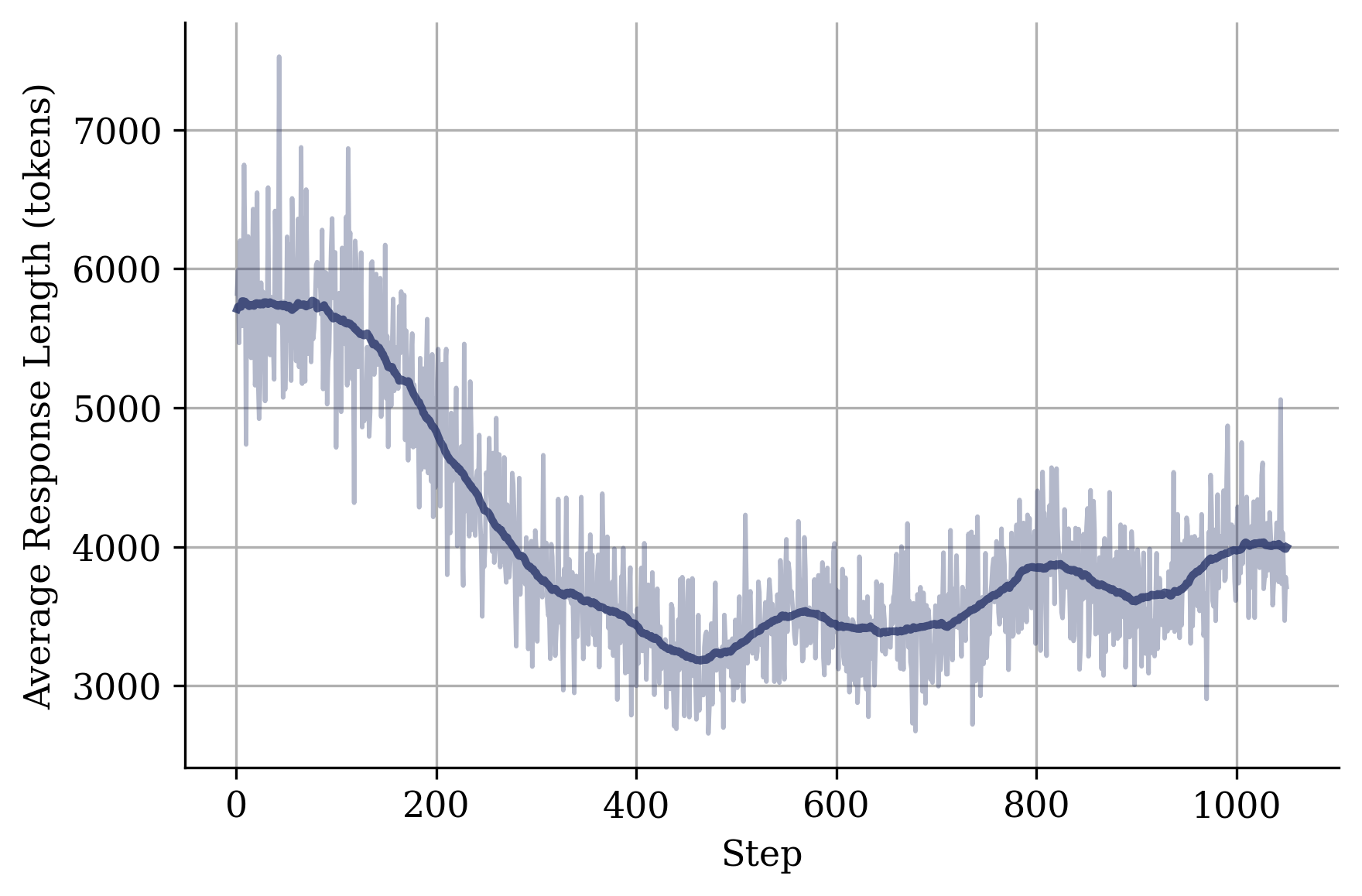
Training reasoning models on a mix of easy and hard problems prevents runaway verbosity by teaching the model that rewards can be obtained with concise solutions.
Core Problem
Standard RLVR pipelines filter out 'easy' problems to maximize gradient signals, leaving only hard problems that require long reasoning chains. This biases models to believe 'longer is better,' leading to excessive verbosity and increased inference costs.
Why it matters:
- Inference latency and compute costs for 'thinking' models (like o1 or R1) are prohibitively high due to extremely long generation sequences.
- Existing methods rely on explicit length penalties which can degrade performance, whereas this approach uses data distribution to implicitly regularize length.
- Models conflate verbosity with reasoning quality, often generating redundant tokens just to reduce uncertainty via longer prefixes.
Concrete Example:
In standard GRPO (Group Relative Policy Optimization), a group of rollouts on an easy problem (1+1=2) yields zero advantage if all are correct, so these are dropped. The model only trains on hard geometry problems requiring 50 steps. Consequently, when later asked a medium-difficulty algebra question, the model hallucinates a 50-step derivation because it has learned that only long answers get rewards.
Key Novelty
Implicit Length Regularization via Easy Samples
- Retains and upweights moderately easy problems (success rate < 1) during RLVR training instead of filtering them out.
- Exposes the policy to short, solvable trajectories that yield positive rewards, counterbalancing the bias toward long chains from hard problems.
- Demonstrates that verbosity can be curbed purely through data curation without modifying the reward function or loss objective.
Architecture
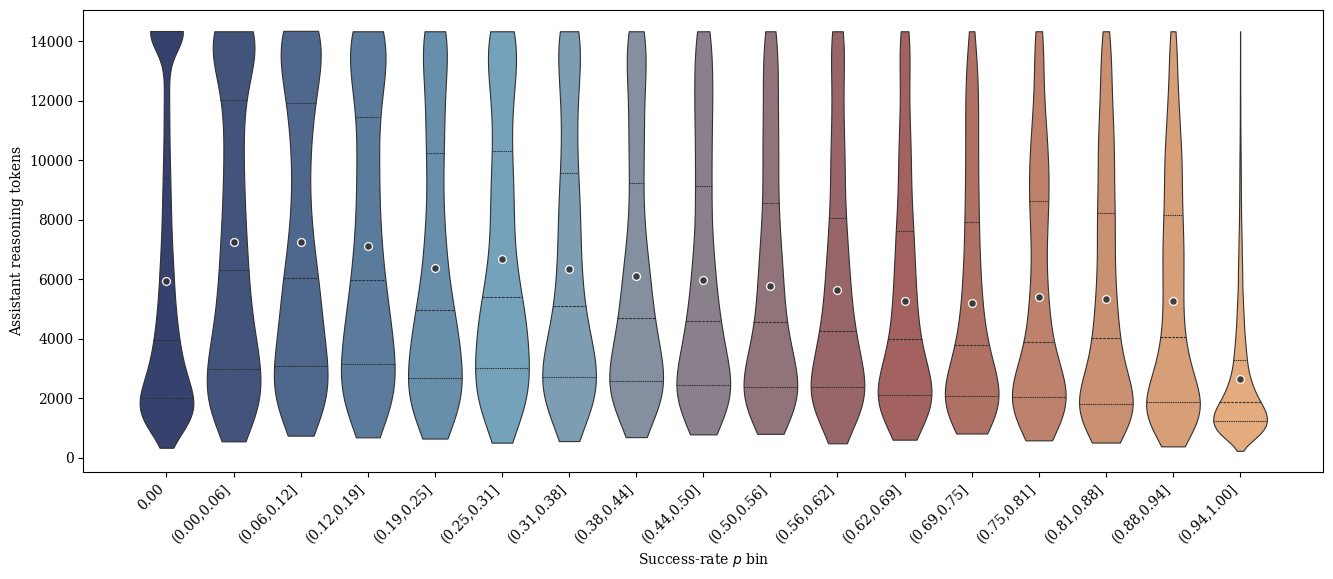
Success rate distribution vs. token length. Left: Token length increases with difficulty. Right: Bimodal success rate distribution (p=0 and p=1) with a sparse intermediate region.
Evaluation Highlights
- Frugal-Thinking-30B-A3B achieves 70.0% Pass@1 on AIME25, significantly outperforming QwQ-32B-Preview (50.0%).
- Reduces average solution length by nearly 2x compared to the initial verbose policy while maintaining baseline accuracy on the AIME25 benchmark.
- Achieves 92.2% Pass@1 on MATH-500 with the 30B model, surpassing the QwQ-32B-Preview baseline of 90.6%.
Breakthrough Assessment
7/10
Simple yet counter-intuitive finding that contradicts standard RLVR efficiency heuristics. Offers a practical, 'free' method to reduce inference costs for reasoning models, though the core innovation is data-centric rather than architectural.