📝 Paper Summary
Remote Sensing
Agentic Reinforcement Learning
Visual Question Answering (VQA)
By cold-starting multimodal models with Earth-science text-only QA, the system acquires reasoning structures that stabilize and amplify subsequent agentic reinforcement learning for ultra-high-resolution remote sensing.
Core Problem
Multimodal models struggle with ultra-high-resolution remote sensing because they must localize tiny targets in massive pixel spaces, and standard reinforcement learning fails to navigate these vast spaces without structured domain priors.
Why it matters:
- Visual evidence acquisition in 8K+ resolution images is a bottleneck; models often fail to zoom in on the correct tiny regions
- Standard RL agents blindly explore evidence paths without domain rules, leading to unstable optimization and poor generalization
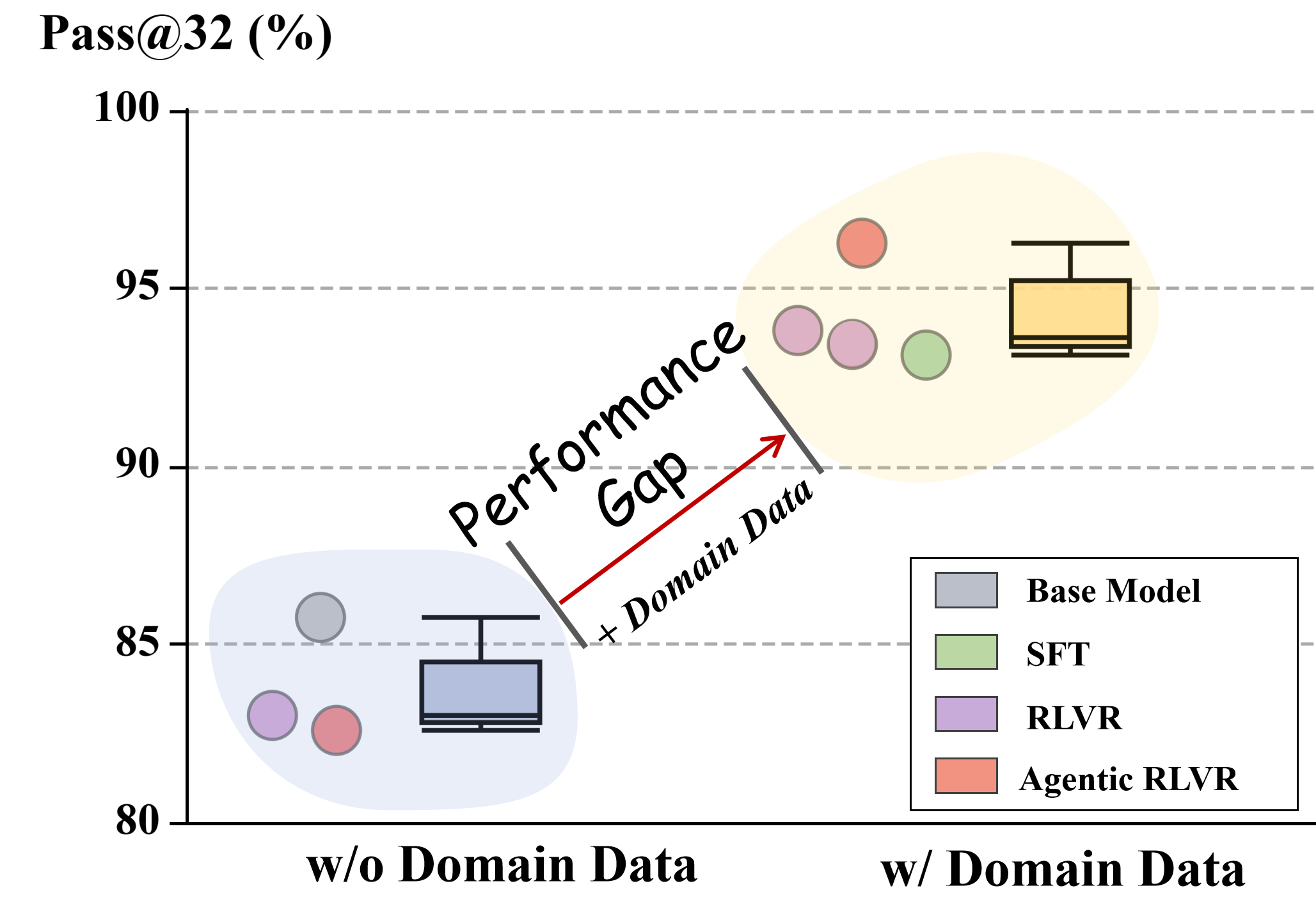
- Existing post-training methods (SFT or RLVR alone) struggle to improve the 'reasoning boundary' (Pass@32) in these specialized scenarios
Concrete Example:
When asked to identify a specific facility in an 8376x8378 pixel image, a standard model might randomly zoom in or fail to find the region. Without text-learned rules (e.g., specific coastal features associated with the facility), the RL agent cannot learn an effective zoom-in policy from scratch.
Key Novelty
Text-Before-Vision Staged Knowledge Injection
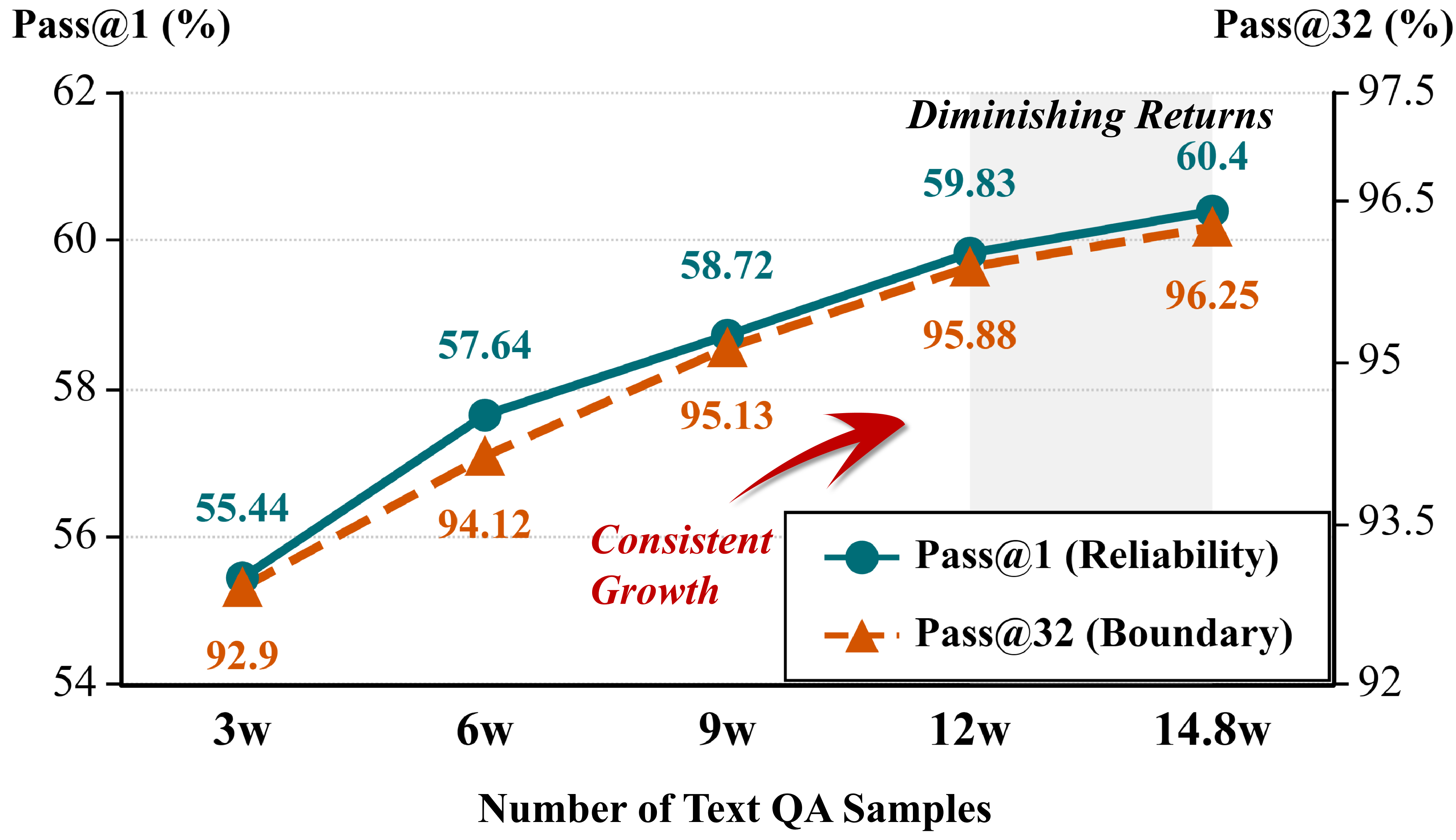
- Cold-start the model with large-scale Earth-science text-only QA to instill domain concepts and reasoning structures (CoT) before visual training
- Use 'Hard-Example Pre-warming': Re-use difficult UHR image-text samples from SFT during the subsequent Agentic RLVR stage to stabilize tool-use learning
Architecture
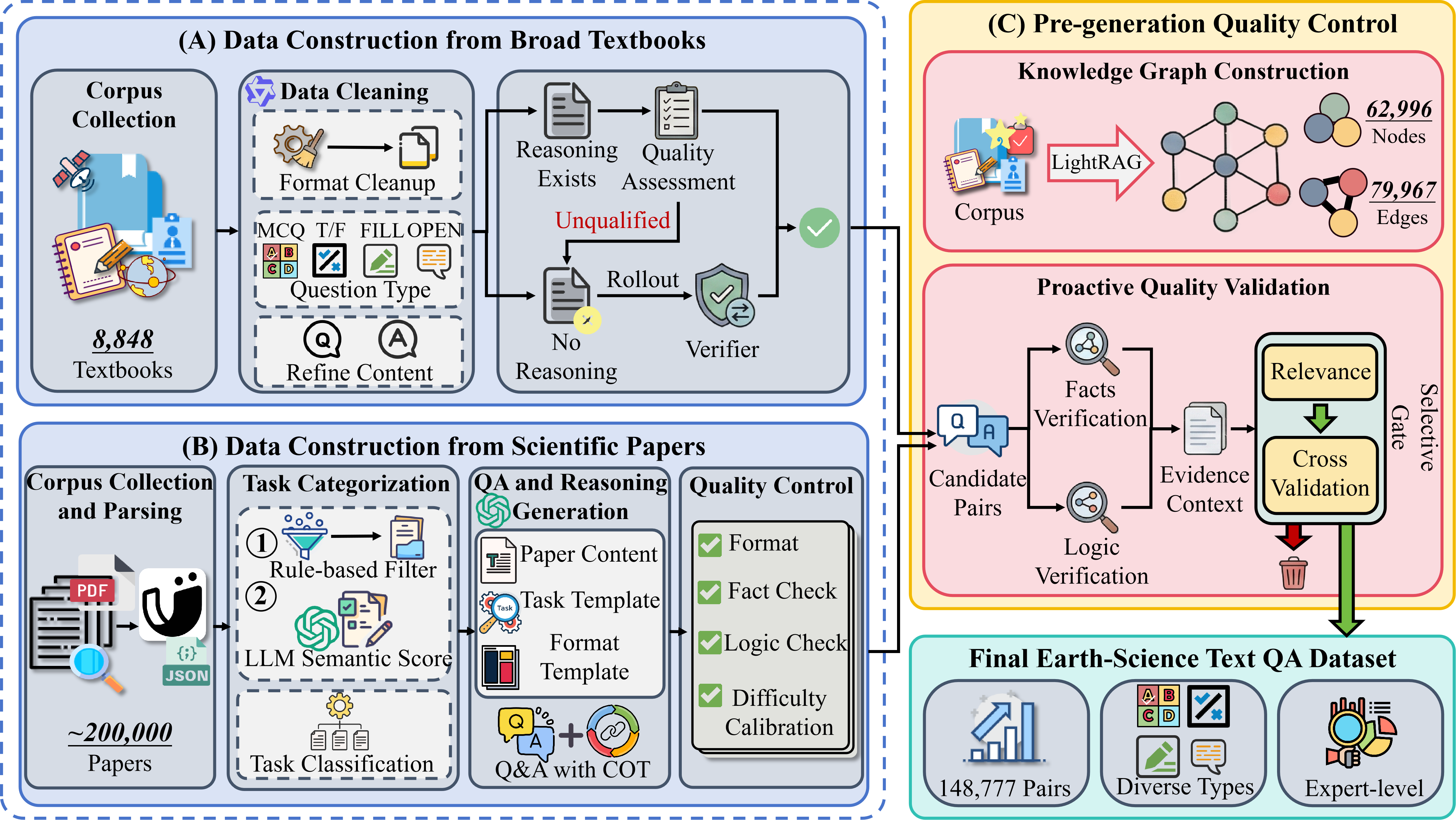
The automated pipeline for Earth-science text QA data generation and quality control.
Evaluation Highlights
- Achieves 60.40% Pass@1 on XLRS-Bench, establishing a new state-of-the-art
- Significantly outperforms larger general-purpose models (e.g., GPT-5.2, Gemini 3.0 Pro, Intern-S1) on UHR remote sensing tasks
- Removing Chain-of-Thought (CoT) from the text cold-start data causes a massive -5.91 drop in Pass@1, proving text structure drives performance
Breakthrough Assessment
8/10
Counter-intuitive finding that text-only data drives vision-heavy UHR performance. Sets new SOTA on a challenging benchmark and proposes a replicable data/training pipeline.