📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Data Selection
CROPI accelerates reasoning model training by selecting influential data using an efficient off-policy gradient estimator that avoids costly online sampling.
Core Problem
Applying theoretically grounded influence functions to RLVR is impractical because estimating the gradient of an evolving policy requires computationally prohibitive new rollouts for every data point.
Why it matters:
- Current data selection methods rely on heuristics (e.g., difficulty) that lack theoretical guarantees and fail to adapt to the model's changing needs during training
- Standard influence estimation requires computing gradients on current policy samples; doing this 'online' for LLMs is too slow and expensive due to inference latency
- High-dimensional gradients in large language models create massive storage and computation bottlenecks for influence-based selection
Concrete Example:
In a standard RLVR loop, to decide if a math problem is useful for the current policy, one would need to generate multiple solutions (rollouts) to estimate its gradient. Repeating this for a 50k dataset at every training step is computationally impossible.
Key Novelty
Curriculum RL with Off-Policy Influence Guidance (CROPI)
- Estimates the 'influence' of data points on the current policy using trajectories collected from an *old* behavior policy (off-policy), eliminating the need for real-time rollouts
- Compresses massive gradient vectors using a sparse random projection technique that randomly drops dimensions before projection, efficiently preserving influence scores (inner products) with less noise
- Iteratively selects a small subset of data that maximizes predicted influence on a validation set, creating a dynamic curriculum that evolves with the model
Architecture
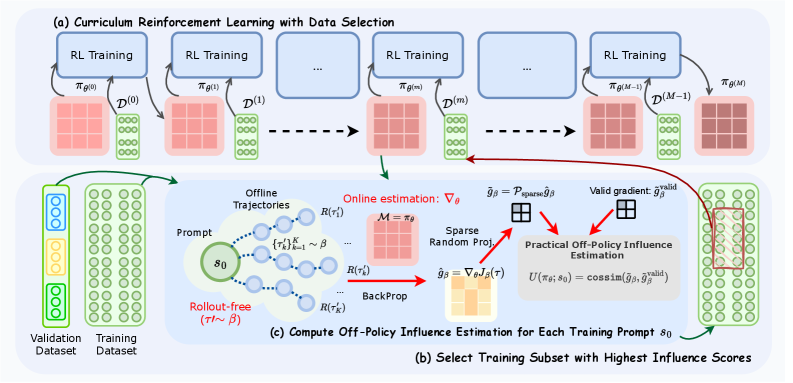
The CROPI framework workflow: (a) Offline trajectory collection, (b) Sparse random projection of gradients, (c) Off-policy influence estimation, and (d) The curriculum loop.
Evaluation Highlights
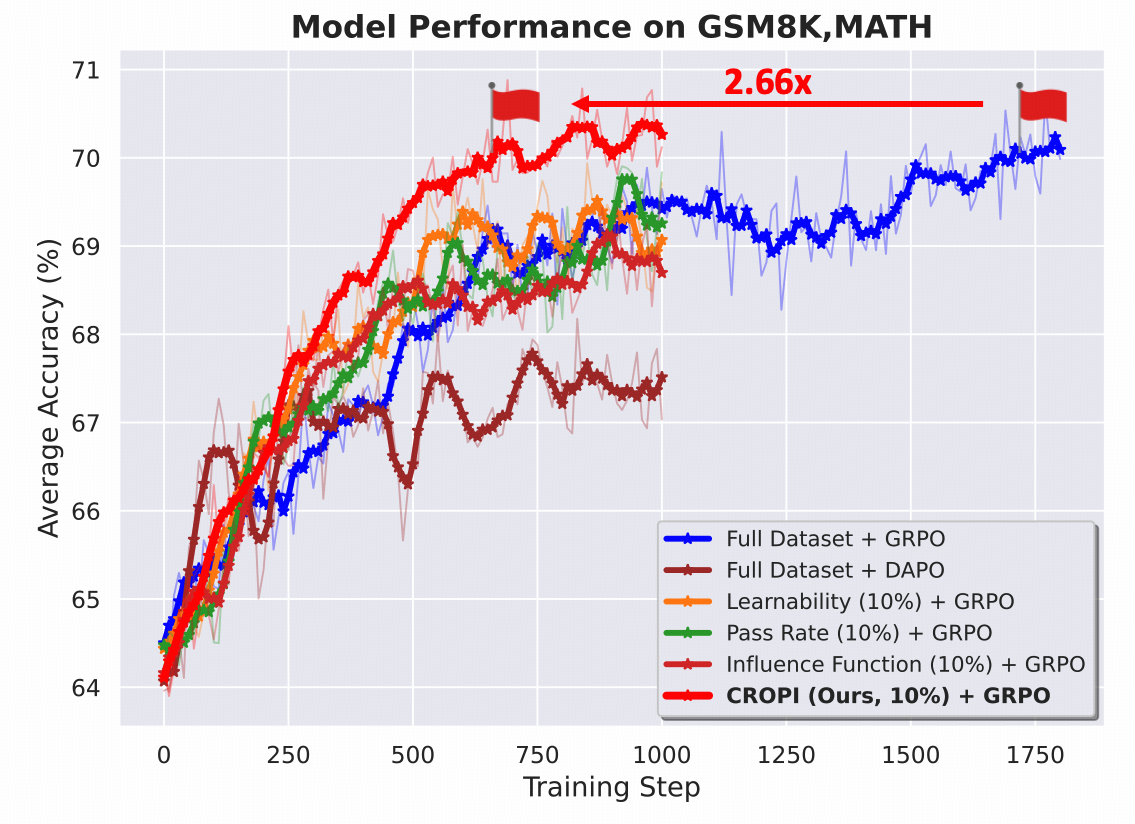
- Achieves 2.66x step-level acceleration on Qwen2.5-1.5B compared to full-dataset training while using only 10% of the data per stage
- Consistently outperforms heuristic baselines (Learnability, Pass Rate) and global influence methods across GSM8K and MATH benchmarks
- Demonstrates robust generalization to 'untargeted' tasks (test sets not used for validation data selection)
Breakthrough Assessment
8/10
Successfully adapts influence functions—a rigorous but expensive tool—to the RLVR setting by solving the primary bottleneck (rollout cost). The speedup claims are significant.