📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
LLM Reasoning
Post-training alignment
RLPR extends reinforcement learning for reasoning to general domains by using the model's intrinsic probability of generating the correct reference answer as a reward signal, removing the need for external verifiers.
Core Problem
Current RLVR methods rely on domain-specific verifiers (like math rule-checkers), which are impossible to build for free-form general reasoning and too costly to train as separate models.
Why it matters:
- Limits powerful RL reasoning techniques to narrow domains like math and code, missing the vast majority of general tasks
- Training separate verifier models requires extensive data annotation and introduces high computational overhead during training
- Rule-based verifiers cannot handle the high diversity and complexity of natural language answers in general domains
Concrete Example:
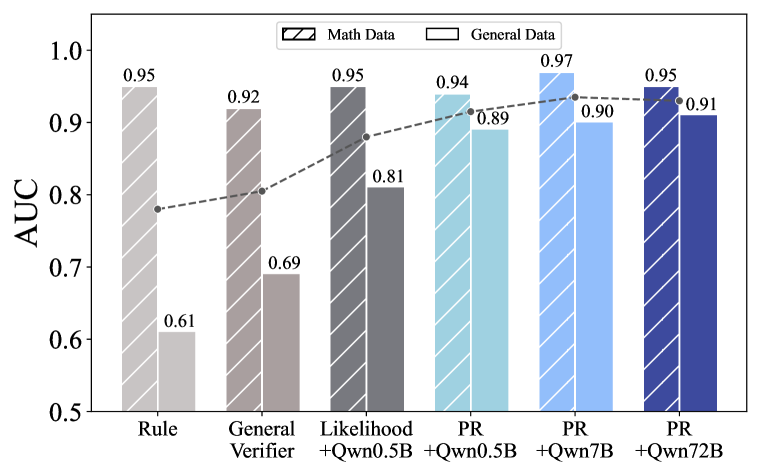
A rule-based verifier might reject a correct answer phrased differently (e.g., synonyms) than the reference. Conversely, a probability-based reward can assign high scores to 'HO' in a chemical context even if the exact string match fails, whereas a rule-based system might score it zero.
Key Novelty
Reinforcement Learning with Reference Probability Reward (RLPR)
- Uses the LLM's own token probabilities for the ground-truth answer as the reward signal, treating confidence as a proxy for reasoning quality without external judges
- Debiases this signal by subtracting the probability of the answer given *without* reasoning, isolating the gain provided specifically by the Chain-of-Thought process
- Stabilizes training with an adaptive curriculum that filters out prompts where the model shows low reward variance (too easy or too hard), ensuring efficient learning
Architecture
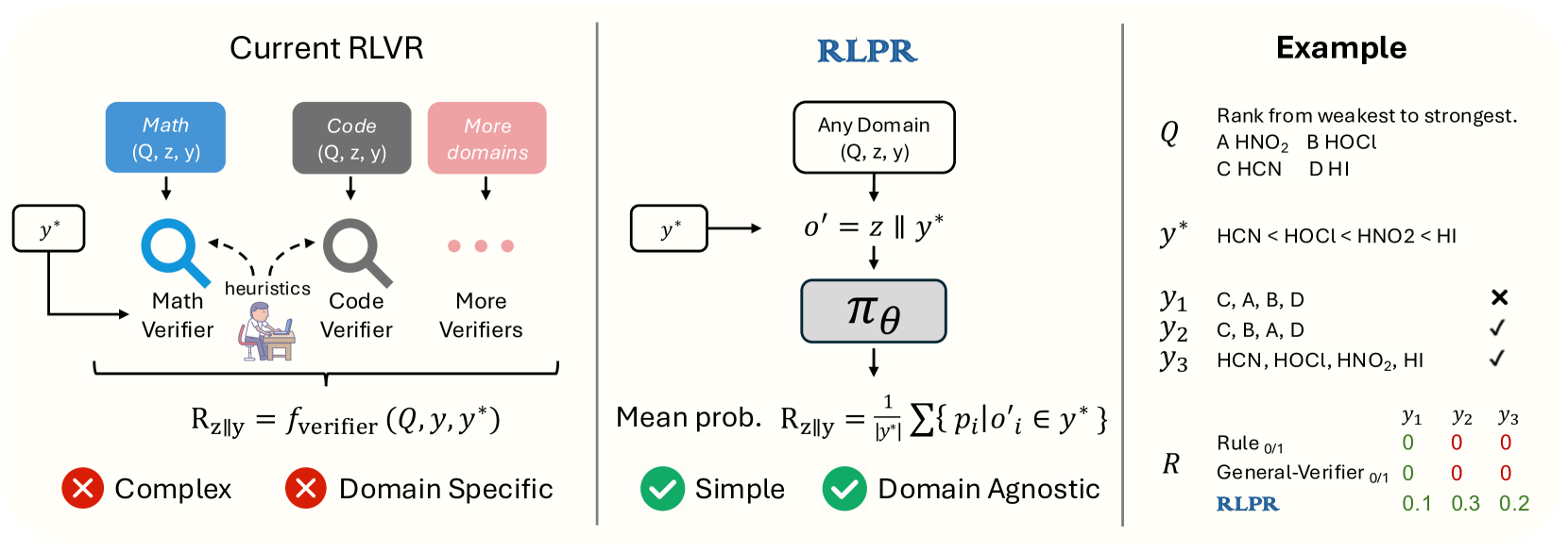
Comparison of Traditional RLVR vs. RLPR pipeline
Evaluation Highlights
- Outperforms concurrent verifier-free method VeriFree by 7.6 points on TheoremQA and 7.5 points on Minerva using Qwen2.5-7B
- Surpasses General Reasoner-7B (which uses a separate 1.5B verifier model) by 1.6 average points across seven benchmarks
- Achieves 56.0 on MMLU-Pro and 55.4 on TheoremQA with Qwen2.5-7B, improving general reasoning by 24.9% over the base model without external verifiers
Breakthrough Assessment
8/10
Significantly expands the applicability of RLVR beyond math/code by removing the verifier bottleneck. The performance gains over verifier-based methods are counter-intuitive and impressive.