📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Synthetic Data Generation
Self-play
SvS is an online self-play strategy where the policy synthesizes difficult variational problems from its own correct solutions, maintaining training entropy and improving Pass@k performance where standard RLVR fails.
Core Problem
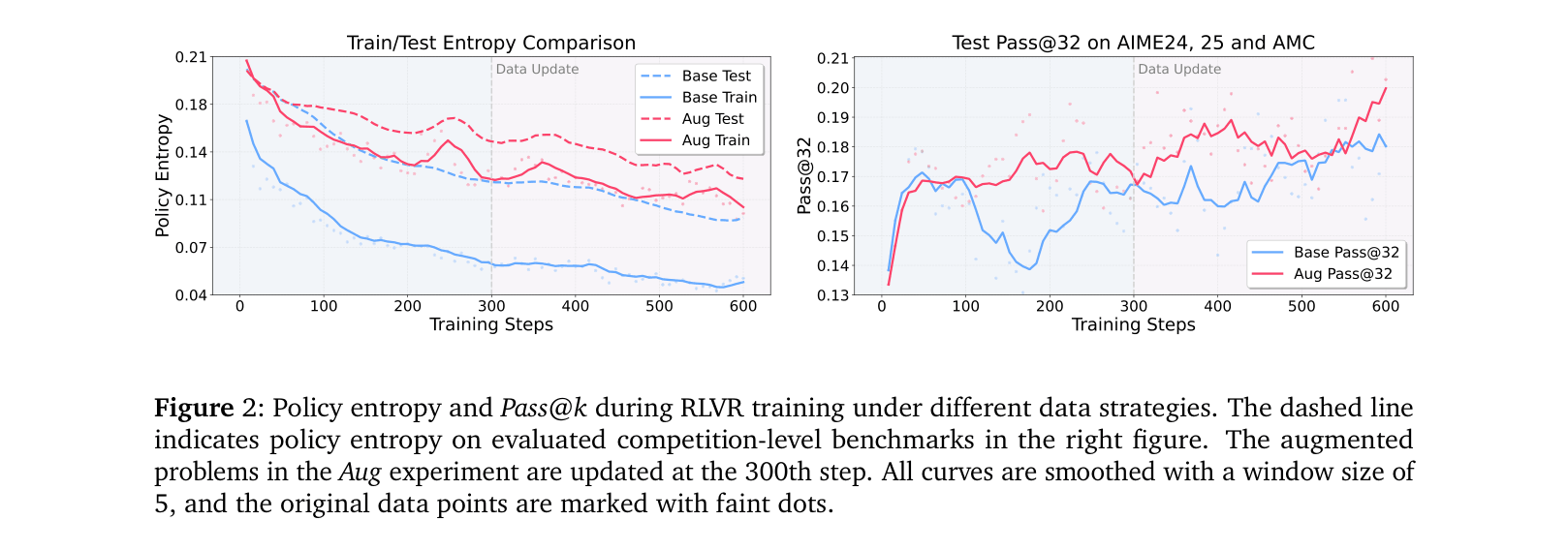
Standard RLVR training improves Pass@1 at the expense of policy entropy (diversity), leading to 'mode collapse' where the model memorizes solutions and stops exploring, causing Pass@k performance to plateau.
Why it matters:
- Pass@k represents the upper bound of an LLM's reasoning capability; failing to improve it limits the model's potential to solve harder problems.
- Current methods for gathering training data (human annotation or external synthesis) lack the precise ground-truth answers required for verifiable reward training.
- Existing RLVR strategies narrow reasoning trajectories toward the most reward-prone solutions, reducing exploration capacity.
Concrete Example:
When training on a limited math set, a standard RLVR policy quickly learns one specific solution path for a problem and repeats it to maximize reward (hacking). Consequently, its entropy drops to zero, and it fails to solve variations of that problem or harder problems requiring novel reasoning steps.
Key Novelty
Self-play with Variational Problem Synthesis (SvS)
- Uses the policy's own correct solutions to challenging problems as context to generate 'variational problems' (rephrased/restructured versions) that share the exact same answer.
- Bypasses the need for external answer labeling because the synthetic problems are derived inversely from correct solutions to known problems.
- Introduces a self-improving loop where the policy solves original problems, creates new variations from successes, and then solves those variations, keeping training data fresh and diverse.
Architecture
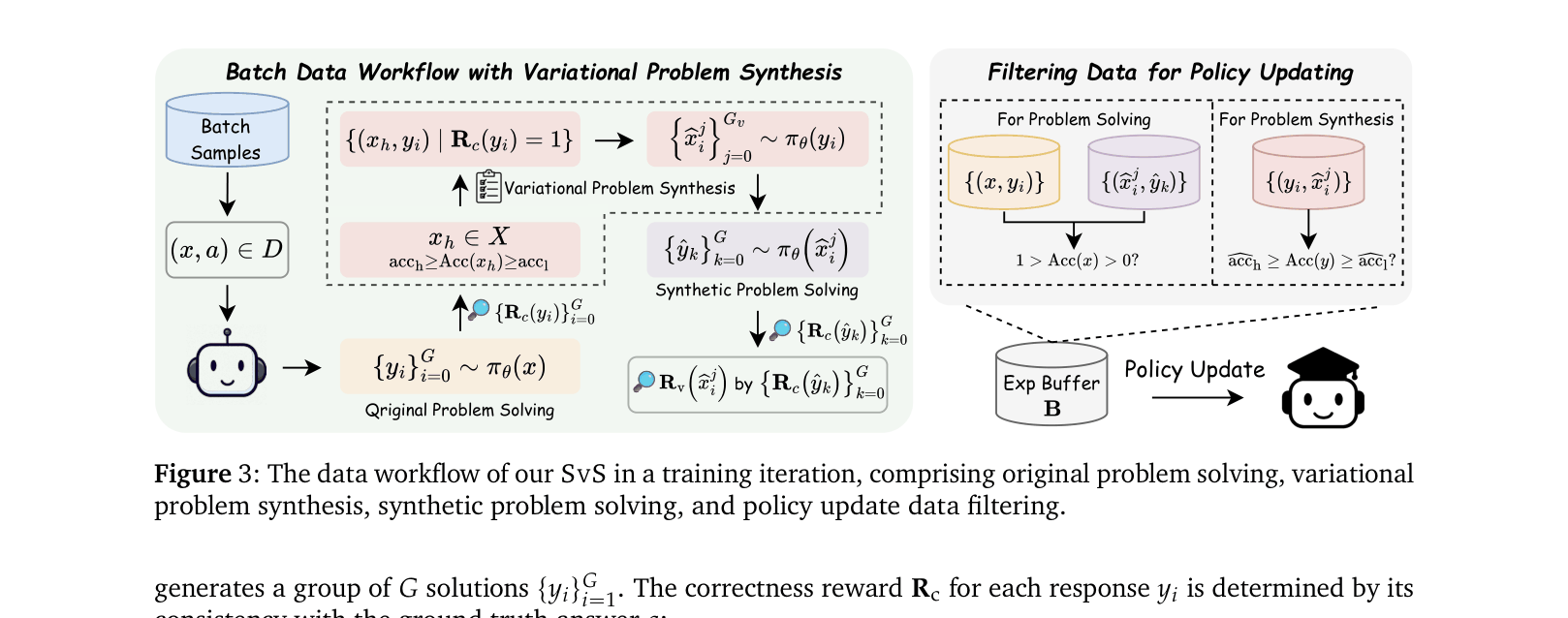
The data workflow loop in a single training iteration of SvS.
Evaluation Highlights
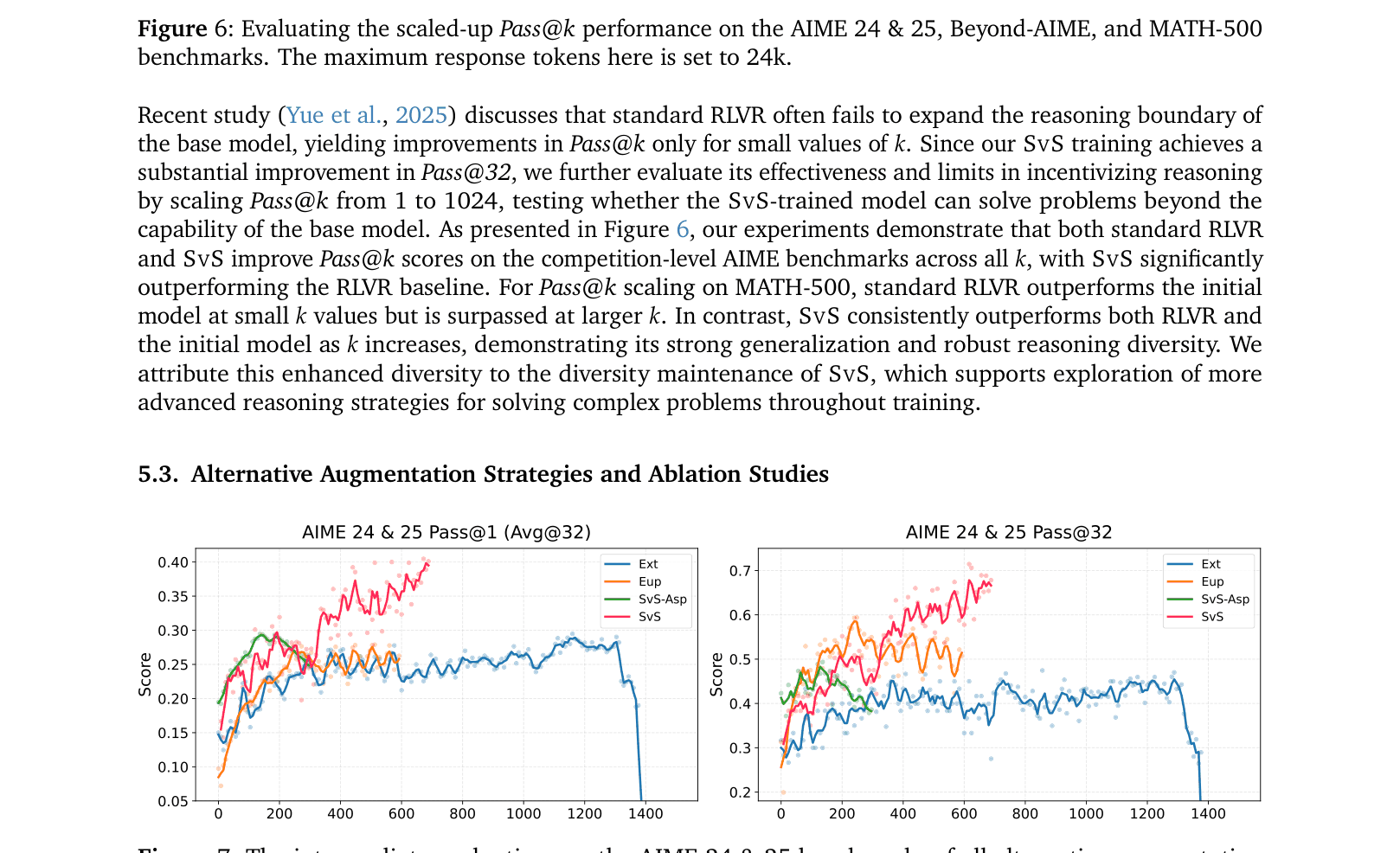
- +18.3% and +22.8% absolute gain on Pass@32 for AIME 24 and AIME 25 benchmarks respectively using Qwen2.5-32B-Instruct compared to standard RLVR.
- Achieves ~3% average absolute improvement over standard RLVR baselines across 12 reasoning benchmarks for models ranging from 3B to 32B parameters.
- Maintains stable policy entropy throughout training, whereas standard RLVR shows a continuous decline (entropy collapse).
Breakthrough Assessment
9/10
Addresses a critical bottleneck in RLVR (entropy collapse/Pass@k plateau) with a self-contained solution requiring no external supervision. The gains on competition math (AIME) are substantial.