📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Post-training for Reasoning
Archer improves LLM reasoning by applying distinct RL constraints to knowledge tokens (low-entropy) versus reasoning tokens (high-entropy), stabilizing facts while encouraging logical exploration.
Core Problem
Standard RLVR treats all tokens equally, or incorrectly isolates them via masking, which breaks semantic dependencies and fails to balance factual stability with reasoning exploration.
Why it matters:
- Uniform RL updates can destabilize factual knowledge while failing to sufficiently encourage exploration for complex reasoning steps.
- Existing methods like gradient masking break the syntactic dependencies between tokens, hindering effective learning of logical patterns.
- Batch-level entropy statistics misclassify tokens in responses that have unusually high or low overall entropy.
Concrete Example:
In a math problem, low-entropy tokens (e.g., 'The answer is') are factual scaffolding, while high-entropy tokens represent logical leaps. If RL updates the factual tokens too aggressively, the model hallucinates; if it masks them entirely, the flow of the sentence breaks, degrading the learning of the subsequent reasoning tokens.
Key Novelty
Archer (Entropy-Aware Dual-Token Constraints)
- Classifies tokens as 'knowledge-related' (low entropy) or 'reasoning-related' (high entropy) using response-level statistics rather than batch-level thresholds.
- Applies synchronous updates to all tokens but with differentiated constraints: stronger KL/stricter clipping for knowledge tokens to preserve facts, and weaker KL/looser clipping for reasoning tokens to promote exploration.
Architecture
Pseudocode of the Archer algorithm showing the flow of entropy calculation, token classification, and dual-constraint loss computation.
Evaluation Highlights
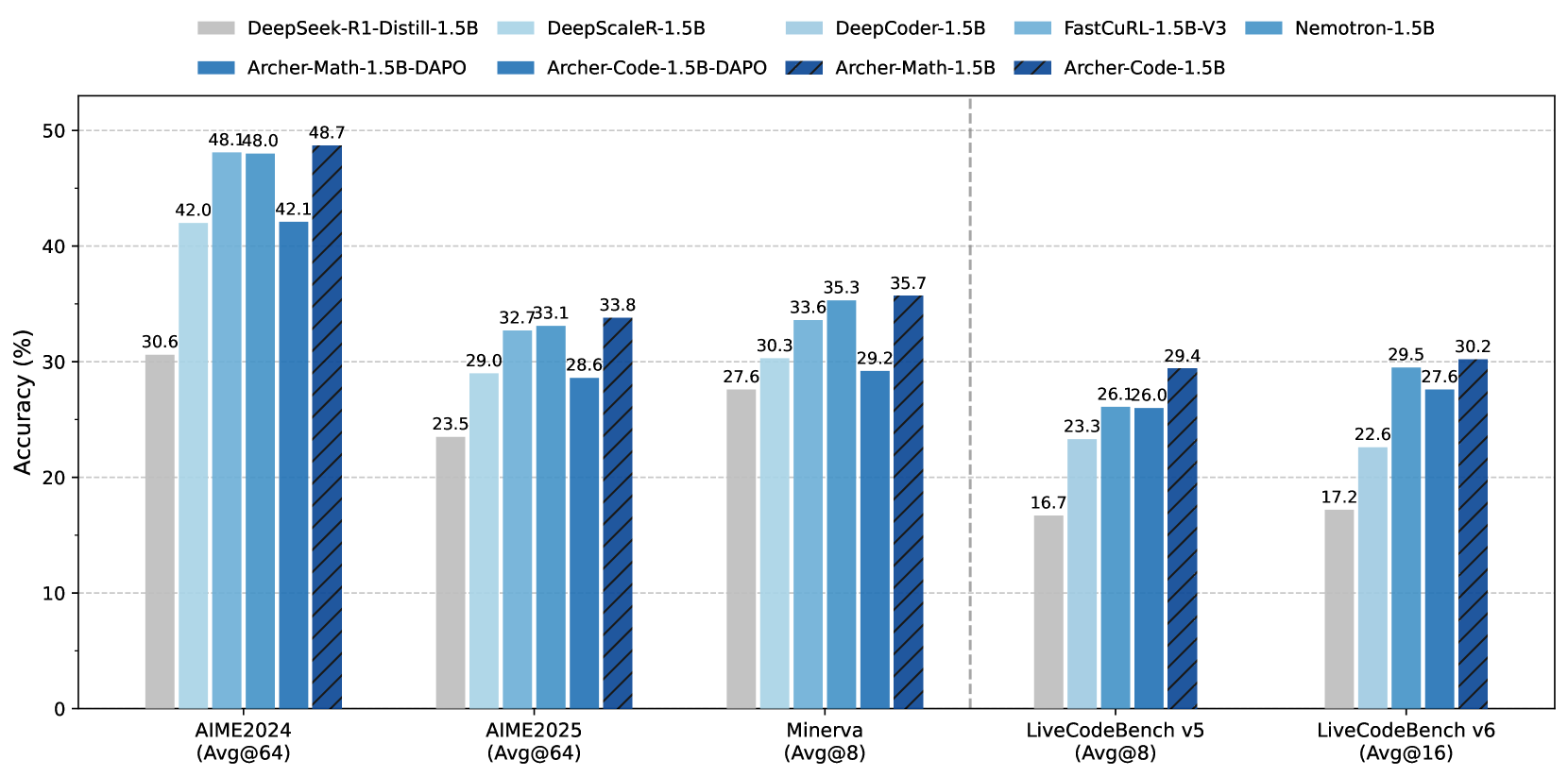
- +6.6% Pass@1 improvement on AIME24 compared to the standard DAPO baseline.
- +5.2% Pass@1 improvement on AIME25 compared to DAPO.
- +3.4% Pass@1 improvement on LiveCodeBench v5 compared to DAPO.
Breakthrough Assessment
8/10
Offers a nuanced, theoretically grounded improvement over standard RLVR by addressing the stability-plasticity dilemma at the token level. Significant empirical gains on hard benchmarks.

