📊 Experiments & Results
Evaluation Setup
Synthetic State-Tracking Task over Cyclic Group Z_96
Benchmarks:
- Synthetic State Tracking (Compositional Reasoning / Path Integration) [New]
Metrics:
- Success Rate (Terminal Reward)
- Peak Attention-Hit Rate (Alignment Metric)
- Statistical methodology: Averaged over 30 batches of size 512
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Fixed-length training demonstrates that RL fails on long horizons without a curriculum, while short horizons are learned easily. | ||||
| Synthetic State Tracking | Success Rate | 1.0 | 0.0 | -1.0 |
| Mixed-length training results show how difficulty ratio affects learning dynamics (Relay vs. Grokking). | ||||
| Synthetic State Tracking (Mixed Length) | Success Rate (L=45) | 0.0 | 1.0 | +1.0 |
| Synthetic State Tracking (Mixed Length) | Convergence Speed / Plateau Length | Not reported in the paper | Not reported in the paper | Not reported in the paper |
Experiment Figures
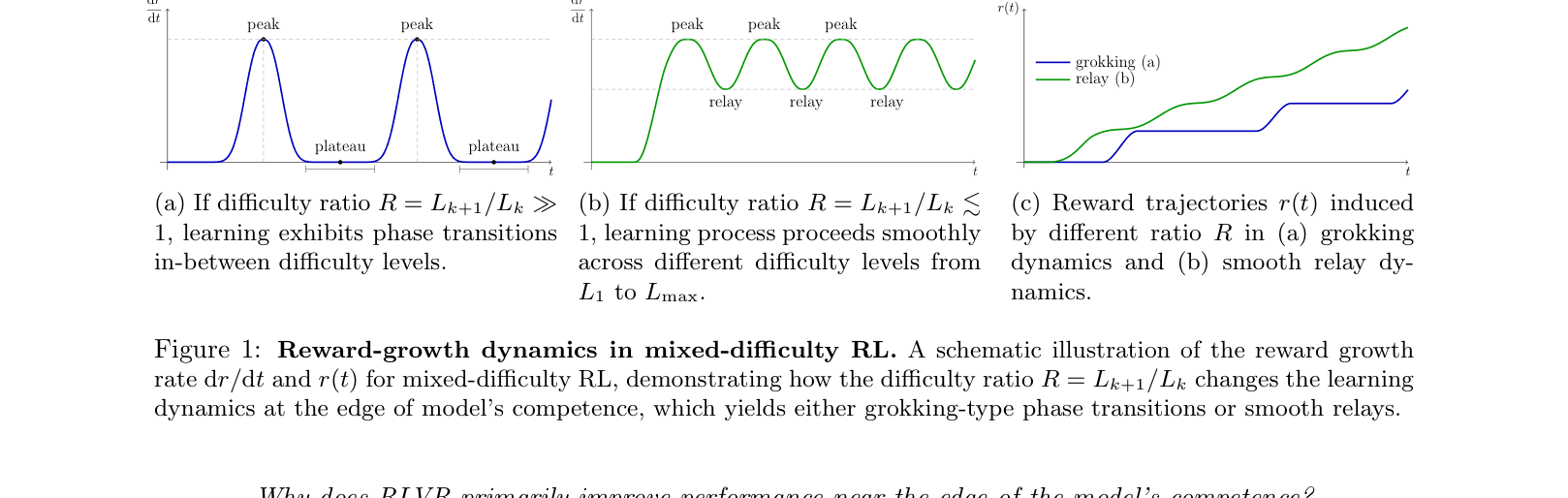
Schematic of Grokking vs. Relay dynamics
Main Takeaways
- Curriculum matters: Outcome-based RL fails on long-horizon tasks unless the training data includes a mixture of easier tasks to bootstrap the gradient signal.
- The 'Relay Effect': When the difficulty gap is small (e.g., ratio R=3), gradients from easier tasks (e.g., L=15) help the model start learning harder tasks (e.g., L=45) before the easy tasks are even fully mastered.
- Grokking mechanism: When the difficulty gap is large (e.g., R=7), the model must fully master the easy task before random successes on the hard task provide enough signal, leading to long plateaus followed by sudden jumps.