📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Synthetic Data Generation
LLM Post-training
GoldenGoose converts unstructured text into verifiable multiple-choice fill-in-the-middle tasks, allowing reinforcement learning to scale on reasoning-rich but previously unverifiable data like textbooks and web scrapes.
Core Problem
Scaling RLVR is bottlenecked by the scarcity of data with automatically verifiable ground truth (like math/code), causing models to saturate or regress when trained for too long on limited datasets.
Why it matters:
- Current RLVR relies on expensive human-authored problems or limited handcrafted environments, excluding vast amounts of reasoning-rich text (e.g., medical diagnoses, theorem proofs) that are hard to verify.
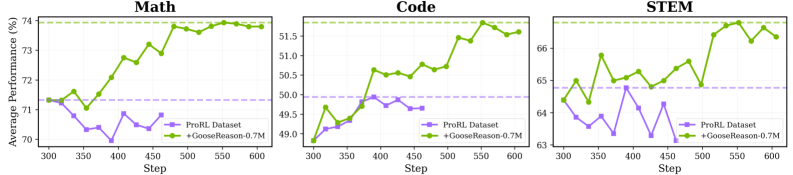
- Models like DeepSeek-R1 and Qwen-4B saturate early (plateauing after ~300 steps) when restricted to existing verifiable datasets.
- Specialized domains like cybersecurity have almost no verifiable training data, preventing the application of modern reasoning RL techniques.
Concrete Example:
In cybersecurity, a raw web scrape about a vulnerability exploit has no ground truth answer to check against. Standard RLVR cannot use it. GoldenGoose takes the text, masks the specific exploit step (e.g., 'buffer overflow'), generates plausible wrong options, and rewards the model for selecting the original text, effectively creating a verifiable task from noise.
Key Novelty
GoldenGoose (Fill-in-the-Middle MCQ Synthesis)
- Transforms any raw text into a Multiple-Choice Question (MCQ) by identifying a key reasoning span, masking it, and treating the original text as the ground truth.
- Uses a teacher LLM to generate diverse, plausible 'distractors' (incorrect options) matching the style of the masked span to ensure the task requires genuine reasoning, not just elimination.
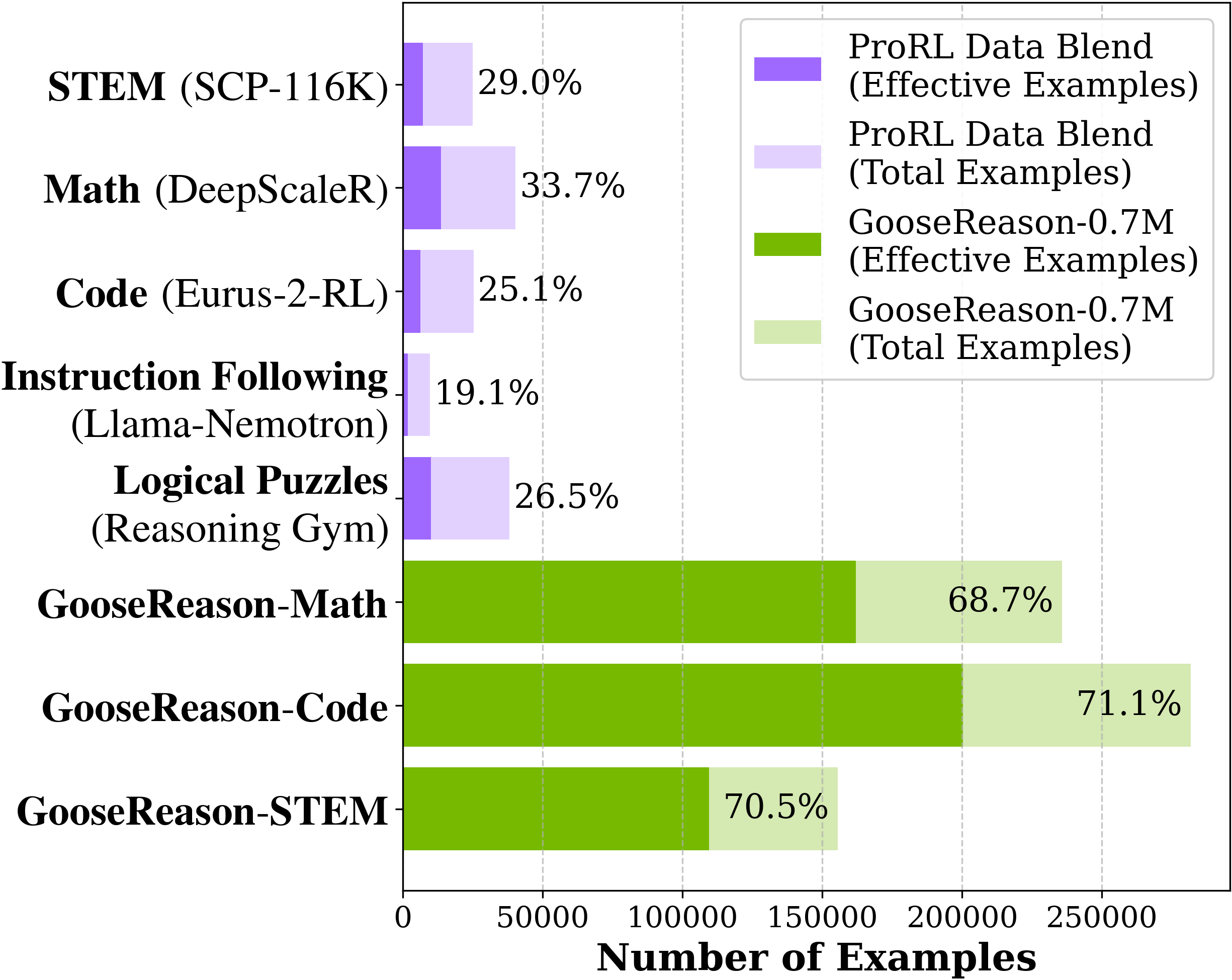
- Enables the use of 'unverifiable' corpora—like unstructured science textbooks or forum discussions—for verifiable reinforcement learning by validating against the original text.
Architecture

The GoldenGoose data synthesis pipeline transforming raw text into RLVR tasks.
Evaluation Highlights
- +3.48% absolute gain in STEM benchmarks for ProRL-1.5B-v2 (a heavily RL-trained model), reviving it from saturation where previous data yielded only +0.13%.
- +4.44% absolute gain across 3 cybersecurity benchmarks for Qwen-4B-Instruct using only 100 RL steps on GoldenGoose-Cyber, establishing a new SOTA.
- Outperforms the domain-specialized Llama-Primus-Instruct (which used extensive pre/post-training) on cybersecurity tasks, despite using a general-purpose base model.
Breakthrough Assessment
8/10
Simple yet highly effective method to unlock unlimited training data for RLVR, addressing the critical data bottleneck. Demonstrated robust gains in both general reasoning and specialized domains.