📊 Experiments & Results
Evaluation Setup
Analysis of weight updates in RLVR checkpoints vs. Base/SFT models
Benchmarks:
- AIME24 (Math Reasoning)
- AMC23 (Math Reasoning)
- MATH500 (Math Reasoning)
Metrics:
- Update Sparsity (bfloat16-aware)
- Principal Angle (Subspace Rotation)
- Spectral Drift (Singular Value Change)
- Jaccard Overlap (Update Consistency)
- KL Divergence (Optimization Trajectory)
- Pass@1 Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Update sparsity analysis shows RLVR modifies significantly fewer parameters than SFT when measured with bfloat16-aware probing. | ||||
| Analysis | Sparsity (bf16) | 2.8 | 53.8 | +51.0 |
| Analysis | Sparsity (bf16) | 0.6 | 69.5 | +68.9 |
| Sparse fine-tuning experiments demonstrate that freezing principal weights (SFT-style) hurts RLVR, while freezing non-principal weights works well. | ||||
| AIME24 | Pass@1 | 56.8 | 55.8 | -1.0 |
| AIME24 | Pass@1 | 56.8 | 48.9 | -7.9 |
| PEFT comparison shows principal-targeted methods (PiSSA) fail to improve over standard LoRA in RLVR. | ||||
| AIME24 | Pass@1 | 50.0 | 30.0 | -20.0 |
Experiment Figures
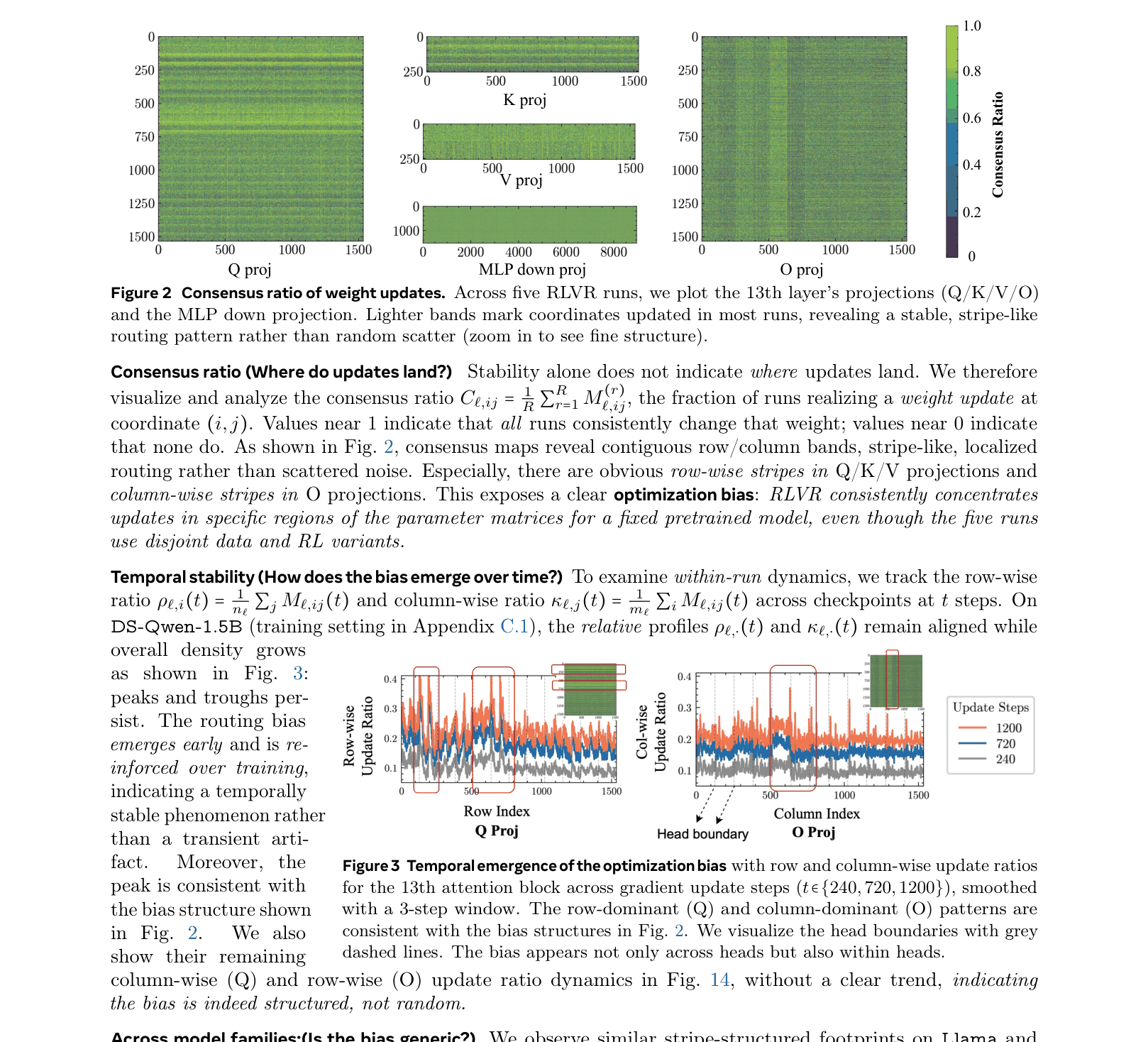
Consensus ratio of weight updates across 5 independent RLVR runs
Main Takeaways
- RLVR updates are highly localized and consistent across different runs/seeds for a fixed pretrained model, indicating a model-conditioned bias
- RLVR preserves the spectral geometry of the pretrained model (singular values, principal subspaces), whereas SFT distorts it
- Intervention study: Random orthogonal rotation of layers destroys the update bias, proving it depends on the specific geometry of the weight matrices
- SFT-era heuristics like 'update principal weights' are harmful for RLVR; effective RLVR updates occur in low-magnitude, off-principal regions