📊 Experiments & Results
Evaluation Setup
Large-scale sampling from Base and RLVR models to estimate solution support overlap
Benchmarks:
- MATH500 (Mathematics problem solving)
- AIME 2024 / AIME 2025 (Challenging mathematics competitions)
- Reasoning Gym (Cognition, geometry, graph theory, games)
- SimpleQA (Factuality evaluation)
- LiveBench (Logic, coding, language comprehension)
Metrics:
- Support Retention Rate (SRR)
- Net Discovery Rate (NDR)
- Net Support Change Rate (NSCR)
- Support Dynamic Score (SDS)
- Pass@k
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Analysis of ProRL-1.5B-v2 on Math Benchmarks shows high retention but negligible discovery. | ||||
| Math Benchmarks (Aggregate) | SRR (Support Retention Rate) | 1.00 | 0.96 | -0.04 |
| Math Benchmarks (Aggregate) | NDR (Net Discovery Rate) | 0.00 | 0.01 | +0.01 |
| Pass@k comparison on AIME 2024 showing the 'invisible leash' effect at high sample counts. | ||||
| AIME 2024 | pass@8192 | 93.3 | 83.3 | -10.0 |
| Comparison of support change counts showing net shrinkage. | ||||
| All Benchmarks (Aggregate) | Count of Correct Completions Change | 48 | 175 | +127 |
Experiment Figures
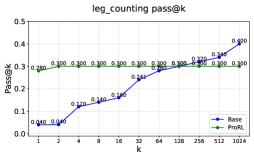
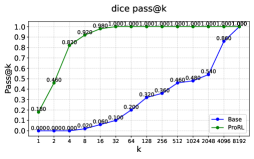
Pass@k curves for Base vs. RLVR models on Reasoning Gym tasks (leg_counting, family_relationships).
Venn diagrams or bar charts comparing solution sets between Base and RLVR models.
Main Takeaways
- RLVR consistently acts as a support-constrained optimization mechanism, with high Support Retention Rate (SRR > 0.90) but very low Net Discovery Rate (NDR < 0.04).
- Across diverse domains (Math, Logic, QA), RLVR loses access to more correct solutions than it gains (Net Support Change Rate is consistently negative).
- There is a divergence between local and global entropy: RLVR models may appear more uncertain at each token step (higher local entropy) but converge to a smaller set of distinct final answers (lower global entropy).
- SFT (Supervised Fine-Tuning) produces moderate support expansion (positive NSCR), whereas RLVR produces support shrinkage, suggesting the 'invisible leash' is specific to the RL objective.