📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Model Calibration
Uncertainty Quantification
UP-RLHF prevents language models from exploiting reward model errors by penalizing the reinforcement learning objective with uncertainty estimates derived from a diverse ensemble of LoRA adapters.
Core Problem
In RLHF, optimizing for higher rewards eventually degrades actual quality (overoptimization) because reward models are imperfect proxies that become overconfident on out-of-distribution samples.
Why it matters:
- Standard KL regularization is often too weak to prevent policy models from drifting into low-quality, out-of-distribution regions where the reward model is hallucinating high scores.
- Overoptimized models produce harmful failures like hallucinated expertise or overly wordy responses, despite receiving high scores from the proxy reward model.
- Existing solutions like enlarging reward models or using full model ensembles are often computationally too expensive.
Concrete Example:
A policy model might generate 'hallucinating information to pretend expertise' (an out-of-distribution sample). A standard reward model might wrongly assign this a high score due to overconfidence. UP-RLHF identifies this as high-uncertainty content via the ensemble and penalizes the reward, preventing the model from learning this behavior.
Key Novelty
Uncertainty-Penalized RLHF (UP-RLHF) with Diverse LoRA Ensembles
- Replaces a single reward model with an ensemble of Low-Rank Adaptation (LoRA) modules to estimate uncertainty (variance) alongside the reward score.
- Enforces diversity among ensemble members by maximizing the 'nuclear norm' of the concatenated LoRA matrices, ensuring they don't collapse into identical predictions.
- Modifies the RL training objective to subtract this uncertainty estimate from the reward, discouraging the model from generating content where the reward model is unsure.
Architecture
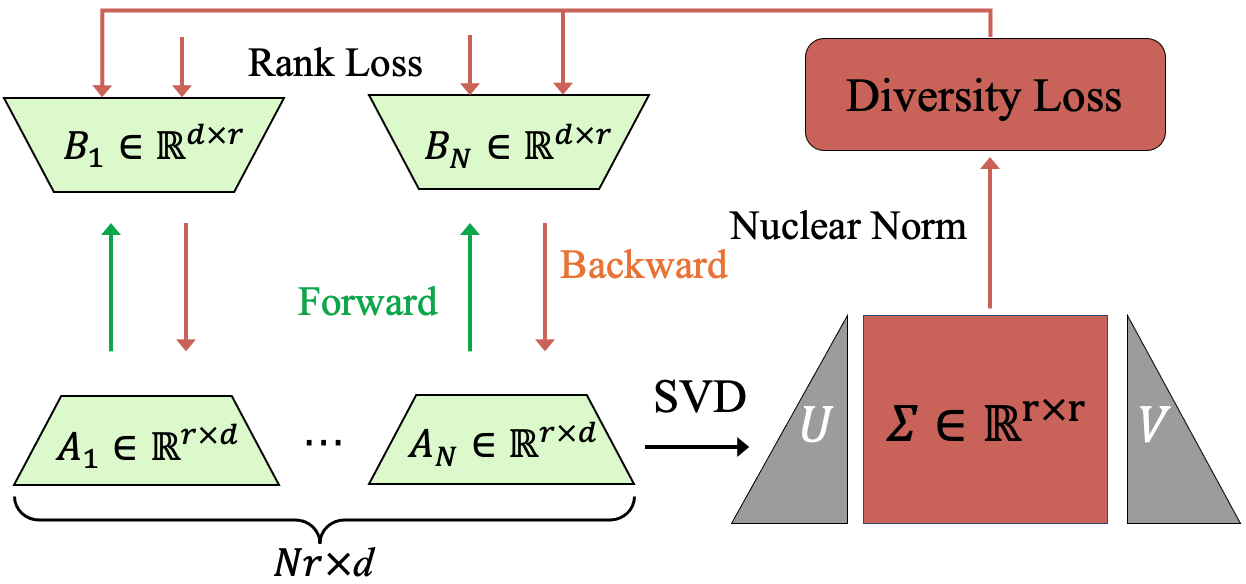
Illustration of the Diverse Reward LoRA Ensemble training process
Evaluation Highlights
- Reduces Expected Calibration Error (ECE) of the reward model from 11.66% to 2.66% on the TL;DR dataset using the diverse LoRA ensemble.
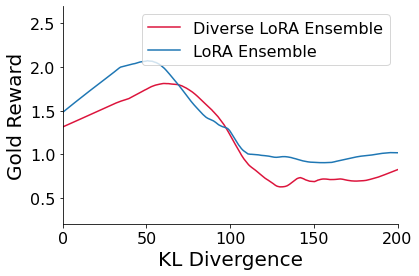
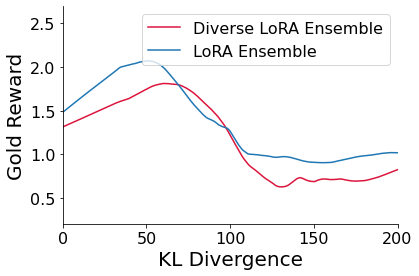
- Improves gold reward performance (human preference proxy) compared to standard RLHF while maintaining lower KL divergence on summarization tasks.
- Eliminates the overoptimization phenomenon where gold reward typically drops after a certain training threshold in standard RLHF.
Breakthrough Assessment
7/10
Addresses a critical RLHF failure mode (overoptimization) with a parameter-efficient solution. The use of Nuclear Norm for LoRA diversity is a clever technical innovation, though the method is an incremental improvement on ensemble-based UQ.