📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
Language models trained via RLHF achieve better downstream performance when guided by moderately accurate reward models rather than highly accurate ones, challenging the assumption that better reward classifiers yield better generators.
Core Problem
The prevailing assumption in RLHF is that higher reward model accuracy leads to better language model alignment, but this relationship is not monotonic.
Why it matters:
- Blindly maximizing reward model accuracy may waste computational resources without improving the final language model
- Highly accurate reward models often lead to overfitting or reward hacking, where the policy exploits the reward function rather than learning the intended behavior
- Understanding this dynamic is crucial for optimizing RLHF pipelines for complex tasks like long-form question answering
Concrete Example:
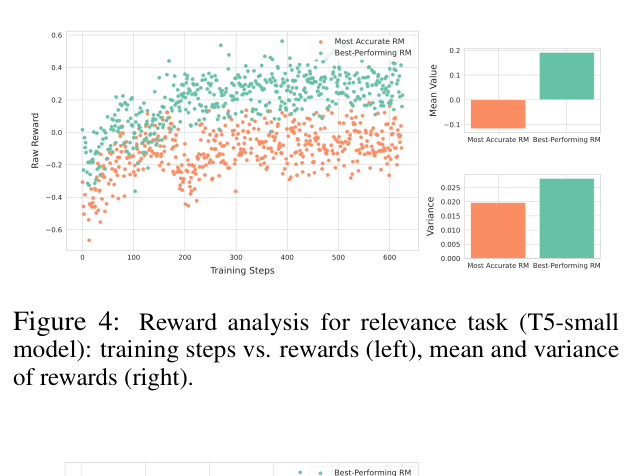
In a completeness task, a highly accurate reward model might assign low, conservative scores to most outputs, failing to provide the gradient signal needed for learning. A moderately accurate model, by providing more variable and aggressive rewards, encourages the generator to explore and eventually produce better text.
Key Novelty
The Accuracy Paradox
- Demonstrates an inverted-U relationship (or non-monotonicity) where intermediate reward model strength yields optimal language model performance
- Shows that highly accurate reward models can be too rigid or conservative, while moderate ones provide 'noisier' but more shaping-friendly feedback that aids exploration
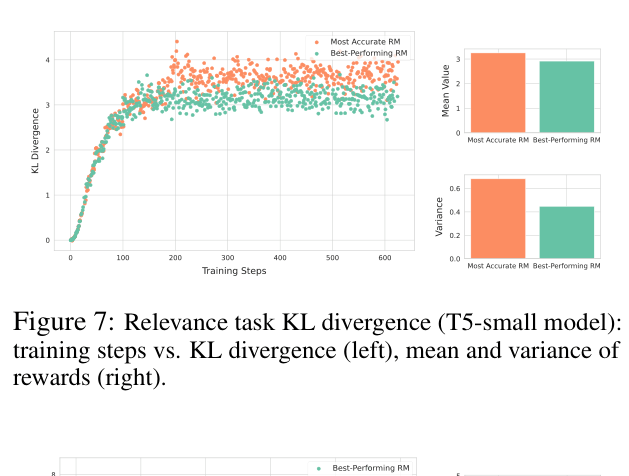
- Identifies that moderate reward models maintain better KL divergence stability, preventing the policy from collapsing into narrow, over-optimized regions
Architecture
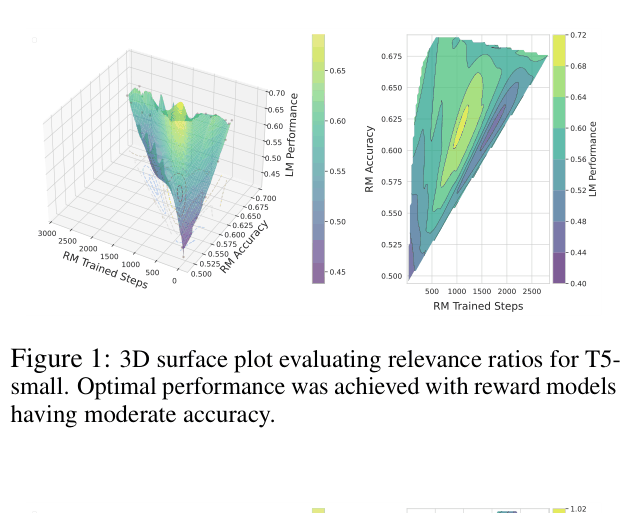
3D surface plots showing the relationship between Reward Model Accuracy, RM Trained Steps, and final LM Performance for the Relevance task (T5-small).
Evaluation Highlights
- In the Relevance task, T5-small trained with a moderate reward model (acc ~0.60) outperformed those trained with the most accurate reward model (acc ~0.70) by roughly +10% in final LM performance score
- In the Factuality task, T5-small achieved peak performance (~0.95 score) with reward models of ~0.72 accuracy, dropping significantly as reward model accuracy approached 0.77
- In the Completeness task, moderate reward models led to final LM scores near 0.8, whereas the highest accuracy reward models suppressed performance to near 0.0
Breakthrough Assessment
8/10
Identifies a counter-intuitive phenomenon that fundamentally challenges standard RLHF practices (simply scaling up reward models). The findings are robust across model sizes and tasks.