📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
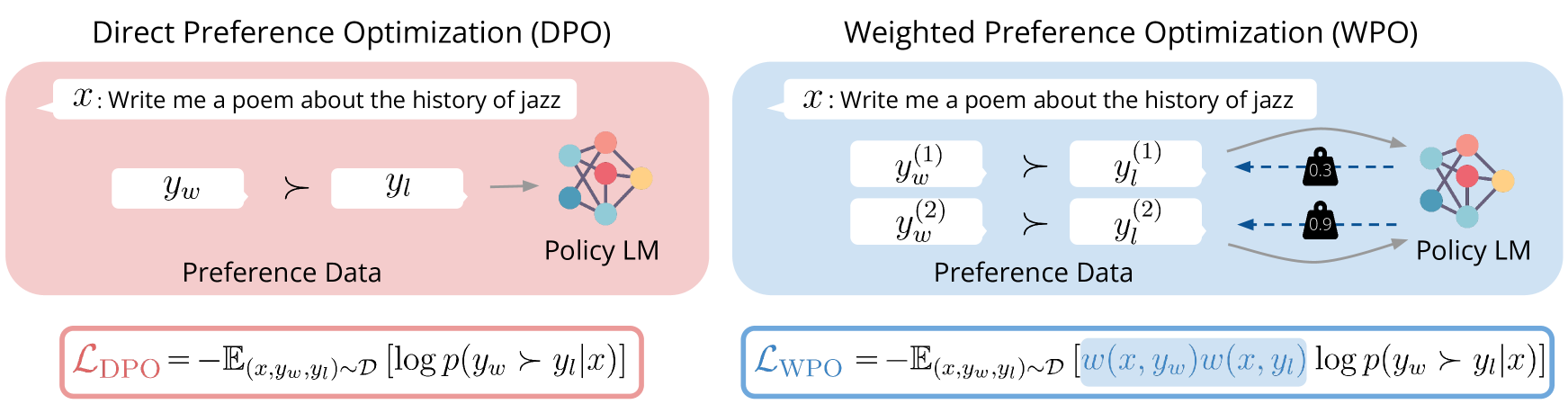
Direct Preference Optimization (DPO)
WPO improves off-policy preference optimization by reweighting training pairs based on their probability under the current policy, effectively simulating on-policy learning without the cost of new sampling.
Core Problem
Off-policy preference optimization (using data generated by other models) suffers from a distributional gap between the data-collecting policy and the target policy, causing the model to learn suboptimally from unlikely or irrelevant examples.
Why it matters:
- Off-policy RL is crucial for scalability and cost efficiency, avoiding expensive online sampling during training
- Treating all off-policy preference pairs equally (as DPO does) ignores that some are far more relevant to the current policy than others, leading to inefficient updates
- Standard DPO often underperforms true on-policy RL due to this distribution mismatch
Concrete Example:
Consider two preference pairs: one generated by the current policy and one by a very different model. DPO treats them equally. WPO recognizes the first is more probable under the current policy and assigns it higher weight, preventing the model from over-fitting to irrelevant, out-of-distribution examples.
Key Novelty
Weighted Preference Optimization (WPO) with Sampled Alignment
- Reweights each preference pair in the DPO loss based on the likelihood of the response being generated by the current policy (simulating on-policy distribution)
- Uses a 'sampled alignment' mechanism to normalize these weights, ensuring that actual on-policy outputs receive consistent high weights regardless of absolute model confidence
- Achieves the performance benefits of on-policy RL while retaining the speed and cost-efficiency of off-policy training
Architecture
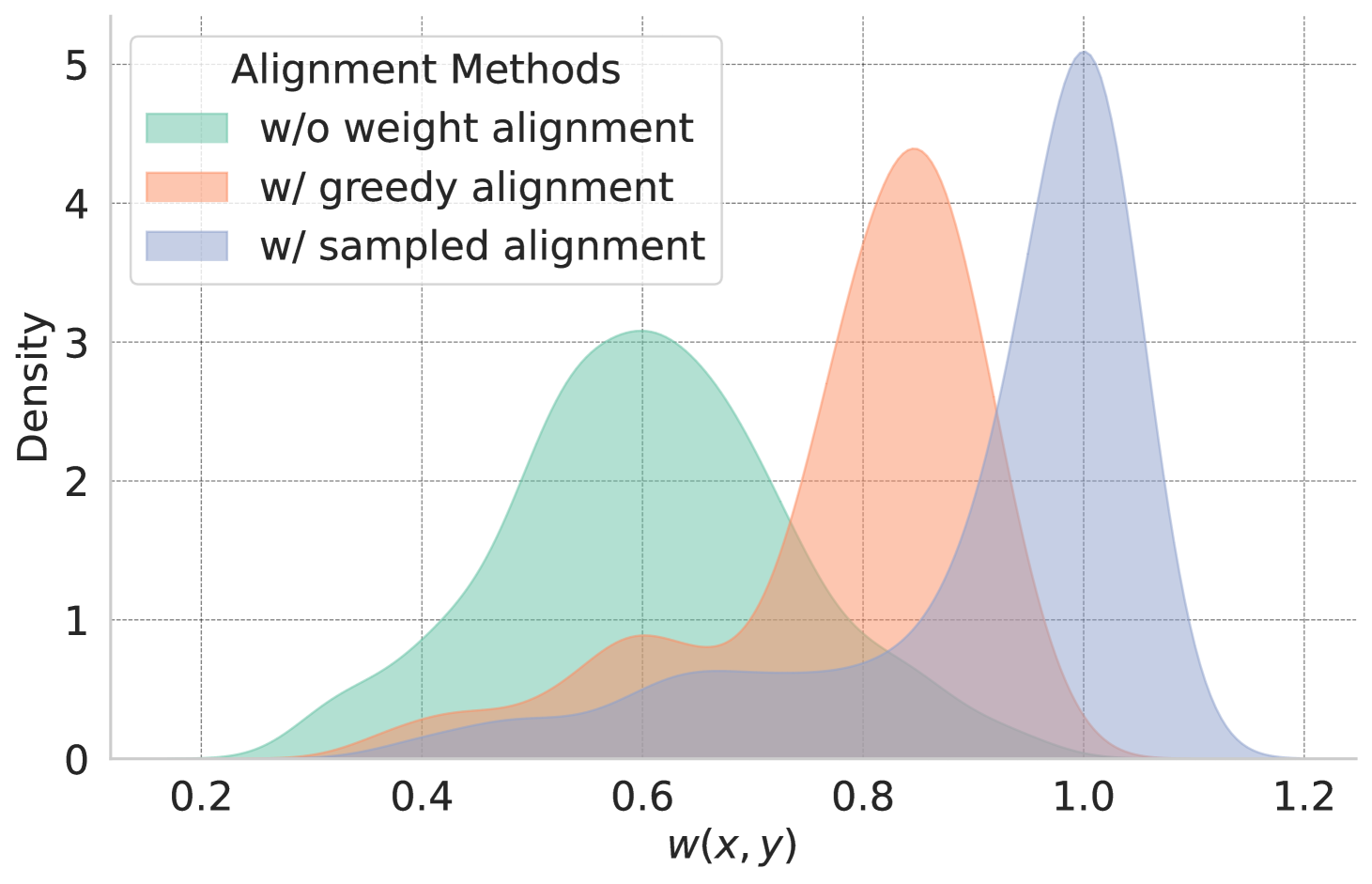
Comparison of weight distributions for different alignment strategies
Evaluation Highlights
- Achieves 76.7% length-controlled winning rate against GPT-4-turbo on Alpaca Eval 2 using Gemma-2-9b-it in a hybrid setting, setting a new SOTA
- Outperforms standard DPO by up to 5.6% on Alpaca Eval 2 in off-policy settings
- Improves length-controlled winning rate by up to 14.9% over the SFT baseline
Breakthrough Assessment
8/10
Simple yet highly effective modification to DPO that addresses a fundamental theoretical gap (off-policy distribution shift) and delivers state-of-the-art empirical results on major benchmarks.