📝 Paper Summary
Multimodal Large Language Models (MLLMs)
AI Safety & Alignment
RLHF-V reduces MLLM hallucinations by collecting segment-level human corrections and optimizing the model with Dense Direct Preference Optimization to prioritize factual segments over linguistic variations.
Core Problem
Existing MLLMs frequently hallucinate content not present in images, and standard RLHF using whole-response ranking suffers from annotation ambiguity and inefficient credit assignment.
Why it matters:
- Hallucinations make MLLMs untrustworthy for high-stakes applications like autonomous driving or assisting visually impaired individuals
- Ranking entire responses is ambiguous when a long response contains both correct details and hallucinations, making it hard for annotators to choose
- Sparse ranking signals (A > B) are inefficient for learning fine-grained factual behaviors, often leading to reward hacking based on non-robust biases (e.g., response length)
Concrete Example:
When describing a clock, a model might correctly identify the object but hallucinate the time. A rank-based annotator struggles to rank this against a response that misses the clock but describes the background correctly. RLHF-V has the human explicitly correct just the time segment.
Key Novelty
Dense Direct Preference Optimization (DDPO) on Segment-Level Corrections
- Collects feedback as specific text segment corrections (e.g., changing 'three dogs' to 'two dogs') rather than ranking full responses, isolating the exact error
- Modifies the DPO objective to calculate response likelihood as a weighted sum, giving significantly higher weight to the corrected segments than unchanged parts
- Treats the corrected response as the positive sample and the original hallucinated response as the negative sample in a supervised optimization framework
Architecture
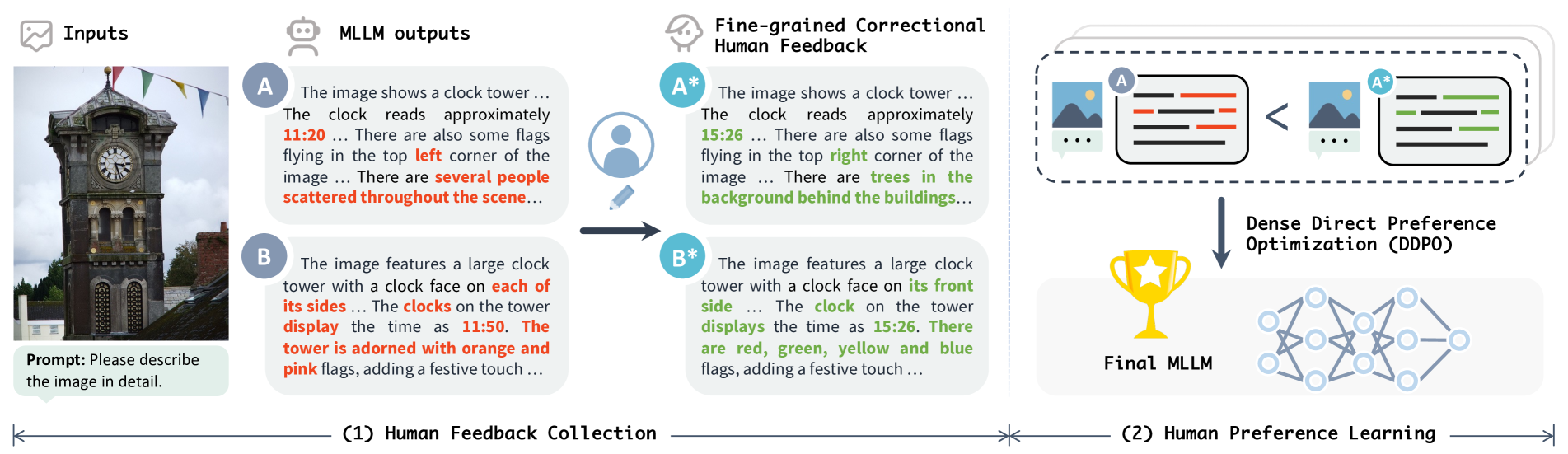
Comparison of traditional RLHF ranking vs. RLHF-V's fine-grained correction. It illustrates how ranking (Option A vs B) is ambiguous when responses have mixed quality, whereas RLHF-V's correction explicitly fixes the 'red' (hallucinated) segments to 'green' (correct) segments.
Evaluation Highlights
- Reduces object hallucination rate of the base MLLM by 34.8% using only 1.4k annotated samples
- Outperforms concurrent LLaVA-RLHF (which used 10k annotated samples) despite using 7x less data
- Demonstrates better robustness than GPT-4V in preventing hallucinations caused by over-generalization in qualitative checks
Breakthrough Assessment
8/10
Significant efficiency gain (beating a 10k-sample baseline with 1.4k samples) and a methodologically sound shift from coarse ranking to fine-grained correction for MLLMs.