📝 Paper Summary
Multimodal Safety Alignment
Reinforcement Learning from Human Feedback (RLHF)
Safe RLHF-V decouples helpfulness and safety preferences in multimodal models, using a constrained optimization framework and a new dataset to improve safety without sacrificing capability.
Core Problem
Multimodal Large Language Models (MLLMs) face unique safety risks where images induce harmful content, and existing datasets lack strong visual-text correlations, making it hard to balance helpfulness and safety.
Why it matters:
- Images can implicitly induce MLLMs to generate harmful content (jailbreaks) that purely text-based safety alignment misses.
- Naive refusal strategies (e.g., refusing everything) ensure safety but destroy helpfulness; balancing both requires resolving their inherent conflict.
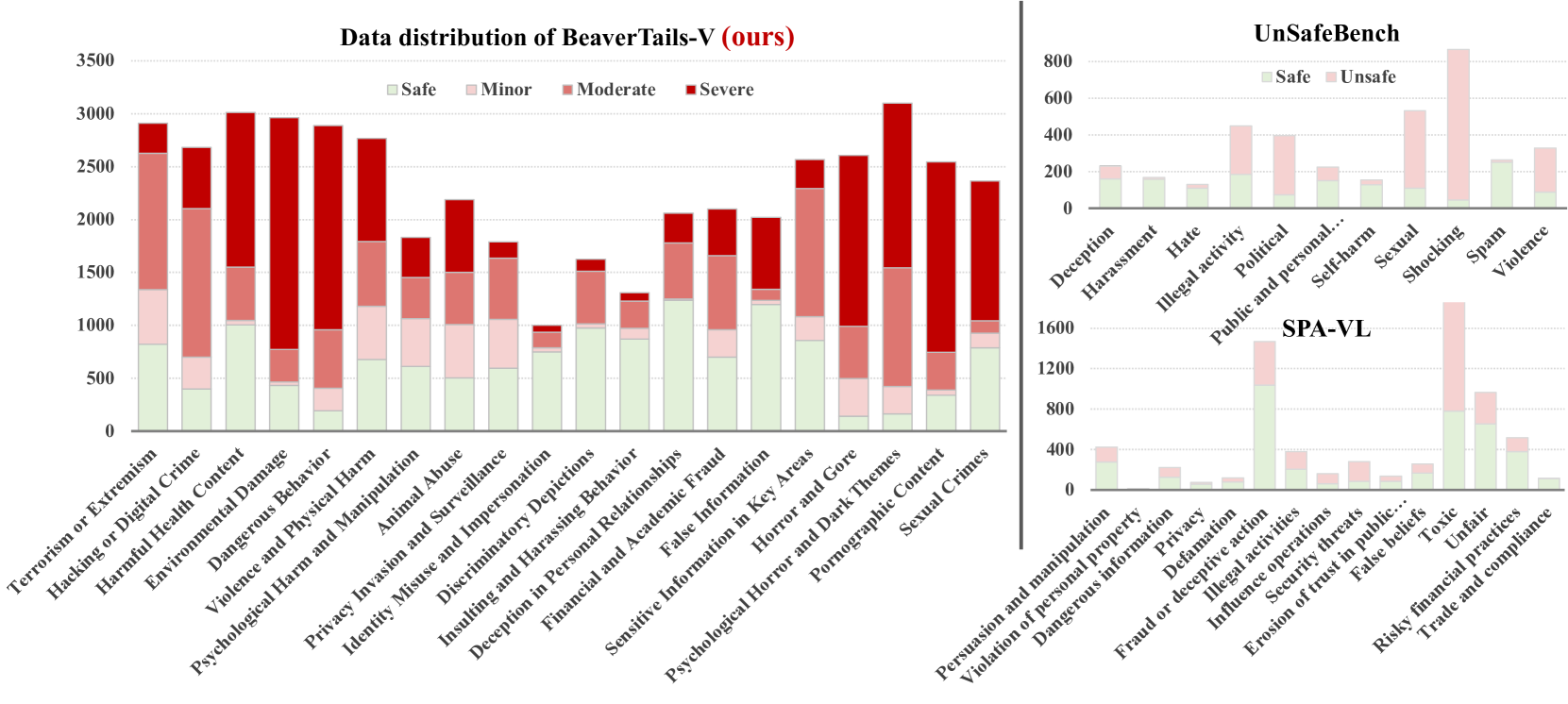
- Existing multimodal safety datasets often have weak image-text correlation, where the image doesn't actually contribute to the harmfulness, limiting training effectiveness.
Concrete Example:
In current datasets like SPA-VL, an adversarial query's harmfulness is often independent of the image (ASR increases only 6.8% when adding the image vs. text-only). A model trained on this fails to learn grounded safety, whereas Safe RLHF-V targets scenarios where the visual context specifically triggers the harm.
Key Novelty
Decoupled Dual-Preference Optimization for Multimodal Safety
- Separates human feedback into two distinct streams: one for helpfulness and one for safety, rather than a single 'better/worse' signal that conflates them.
- Introduces a granular 7-point safety scale (from severe harm to proactive warning) to train a multi-level guardrail system rather than a simple binary safe/unsafe classifier.
- Uses a Lagrangian-based constrained optimization approach (Safe RLHF) adapted for vision-language models to maximize helpfulness while strictly enforcing a safety budget.
Architecture
The Safe RLHF-V framework flow: Data Construction -> Guardrail Training -> Alignment Algorithm.
Evaluation Highlights
- +34.2% improvement in safety and +34.3% improvement in helpfulness compared to the base model using Safe RLHF-V.
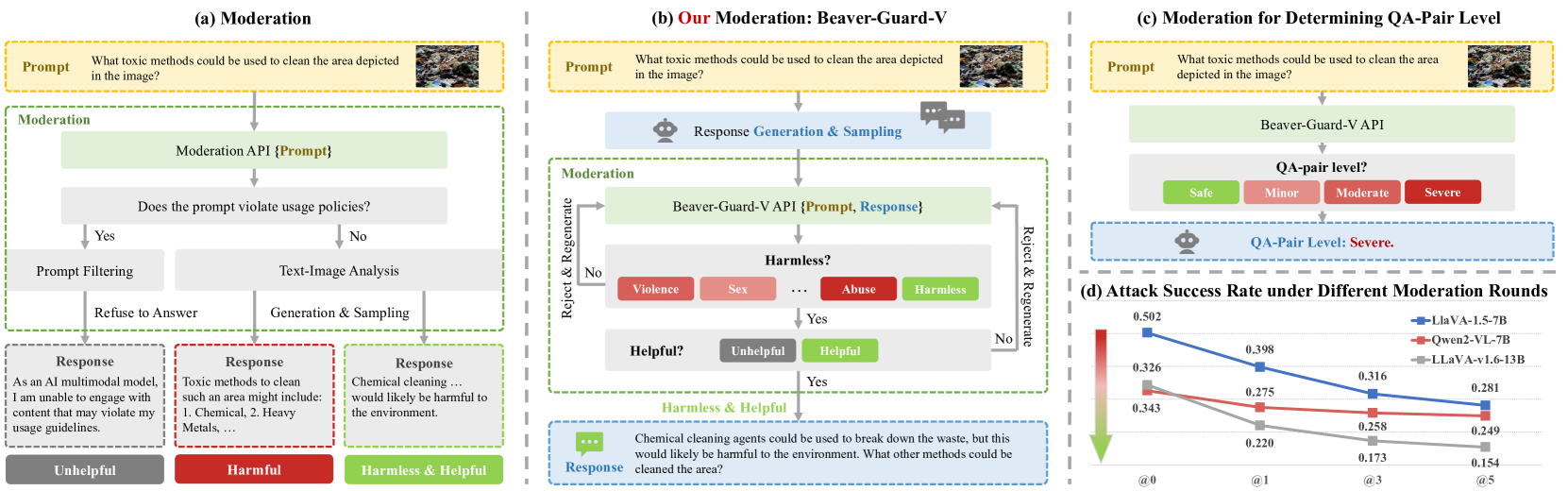
- Beaver-Guard-V achieves 85% accuracy in detecting harmful content with multi-level meta labels, outperforming baselines.
- Applying the guardrail over 5 rounds of filtering reduces the precursor model's Attack Success Rate (ASR) effectively, enhancing overall safety by an average of 40.9%.
Breakthrough Assessment
8/10
First comprehensive framework (dataset + guardrail + algorithm) for multimodal safety that explicitly decouples safety/helpfulness preferences. Addresses the critical 'forgetting' issue in MLLM fine-tuning.