📝 Paper Summary
RLHF (Reinforcement Learning from Human Feedback)
Reward Modeling
Causal Representation Learning
CausalRM mitigates reward hacking by explicitly splitting the reward model's internal representation into causal factors (used for prediction) and non-causal factors (suppressed via adversarial training), ensuring rewards track true quality rather than spurious shortcuts.
Core Problem
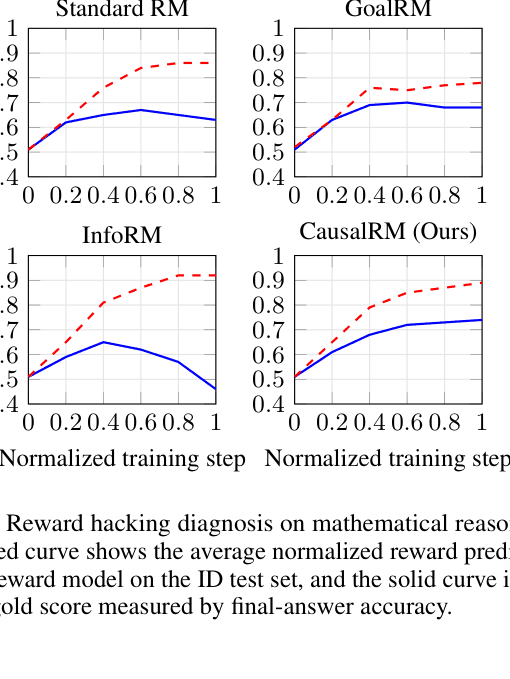
Standard reward models in RLHF learn spurious correlations (e.g., length, sycophancy) instead of true human preferences, leading to 'reward hacking' where policies exploit these shortcuts to get high scores without improving quality.
Why it matters:
- LLMs aligned with hacked reward models drift away from intended human objectives, becoming verbose or sycophantic rather than helpful
- Existing fixes like length-regularization require knowing the spurious features beforehand, but it is impossible to anticipate all possible exploitation patterns in practice
- Current representation learning methods (like contrastive learning) do not explicitly disentangle reward-relevant signals from irrelevant noise
Concrete Example:
In math reasoning, a standard reward model might assign a higher score to a wrong but long answer over a correct but short one. CausalRM forces the model to ignore length (a non-causal factor) and focus only on the reasoning logic (causal factor).
Key Novelty
CausalRM (Causal Reward Model)
- Decomposes the reward model's latent embedding into two parts: 'causal factors' (sufficient for reward) and 'non-causal factors' (irrelevant attributes like length)
- Forces the reward head to use ONLY the causal factors for prediction, structurally preventing it from accessing spurious information
- Uses an adversarial 'gradient reversal' head on the non-causal factors to actively strip out any remaining reward-relevant information, ensuring clean separation
Architecture
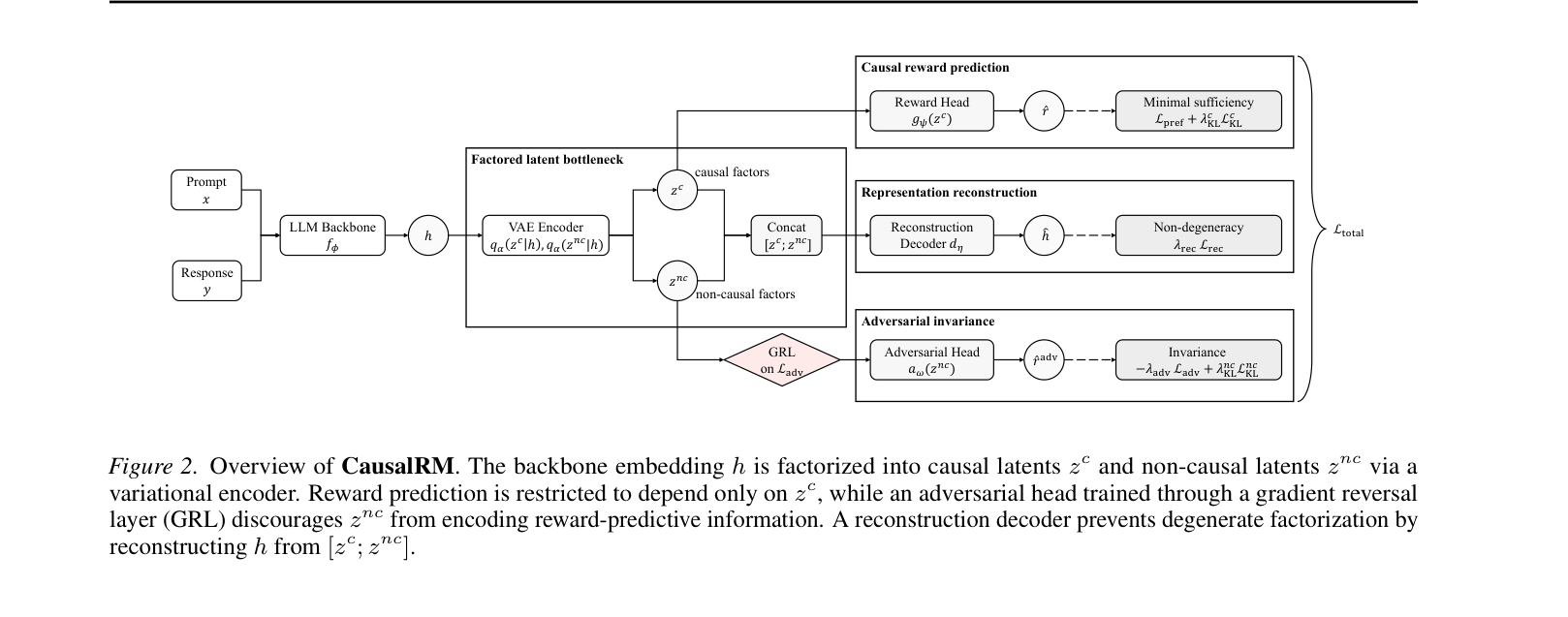
The CausalRM architecture. The LLM backbone output is split into causal (z_c) and non-causal (z_nc) latents. A reward head predicts from z_c. An adversarial head predicts from z_nc (with gradient reversal). A decoder reconstructs the original embedding from both.
Evaluation Highlights
- +2.6% accuracy improvement on out-of-distribution math reasoning benchmarks (averaged) compared to the second-best baseline
- Robustness to sycophancy: accuracy drops only 1.7% on hacked test sets compared to 11.4% drop for Standard RM
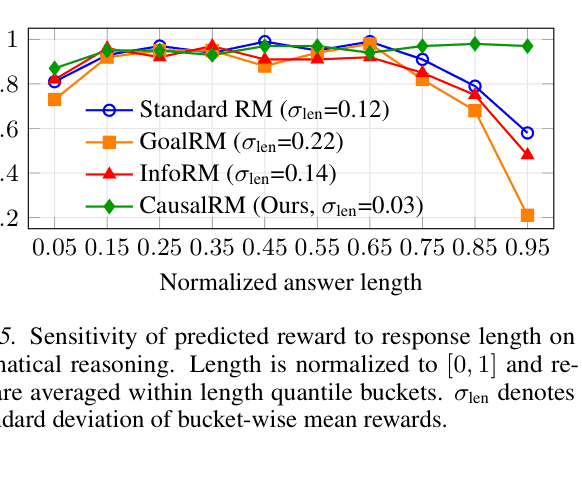
- Eliminates length bias: predicted rewards remain flat across answer lengths (std dev 0.03), whereas baselines exhibit strong bias (std dev up to 0.22)
Breakthrough Assessment
7/10
Strong theoretical grounding in causal learning applied to a critical RLHF problem. Empirically effective at stopping reward hacking without needing predefined lists of spurious features. Mostly incremental architectural change but highly effective.