📊 Experiments & Results
Evaluation Setup
Reward Model training and evaluation on pairwise preferences
Benchmarks:
- Held-out Test Sets (In-distribution Preference Prediction)
- RewardBench (Out-of-distribution Reward Model Generalization (Chat, Reasoning, Safety))
Metrics:
- Accuracy (Evaluation Set)
- RewardBench Accuracy
- Expected Calibration Error (ECE)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Scaling experiments show that increasing data size has diminishing returns, and the rate of improvement varies significantly by dataset. | ||||
| Evaluation Set Accuracy | Average Gain per Doubling | Lower than SafeRLHF | 2.4-4.7% | Highest among datasets |
| Generalization experiments on RewardBench reveal that small, high-quality datasets can outperform large, lower-quality ones. | ||||
| RewardBench (Chat Category) | Performance Rank | Lower Rank | Higher Rank | Positive |
| Noise robustness experiments demonstrate high tolerance to label flipping in reward modeling. | ||||
| Evaluation Set Accuracy | Performance Retention | 100% (Relative Peak) | ~100% (Relative Peak) | ~0 |
| UltraFeedback Evaluation | ECE (Expected Calibration Error) | 0.183 | 0.086 | -0.097 |
Experiment Figures
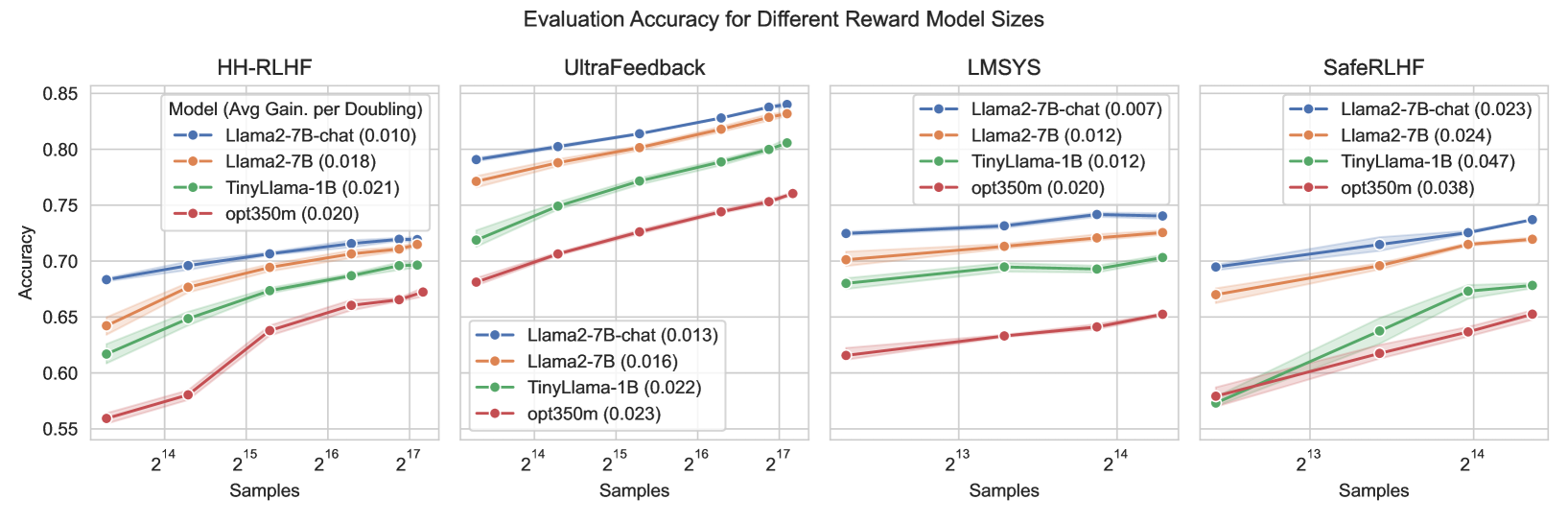
Evaluation set accuracy vs. Training Set Size (log scale) for four datasets across different models.
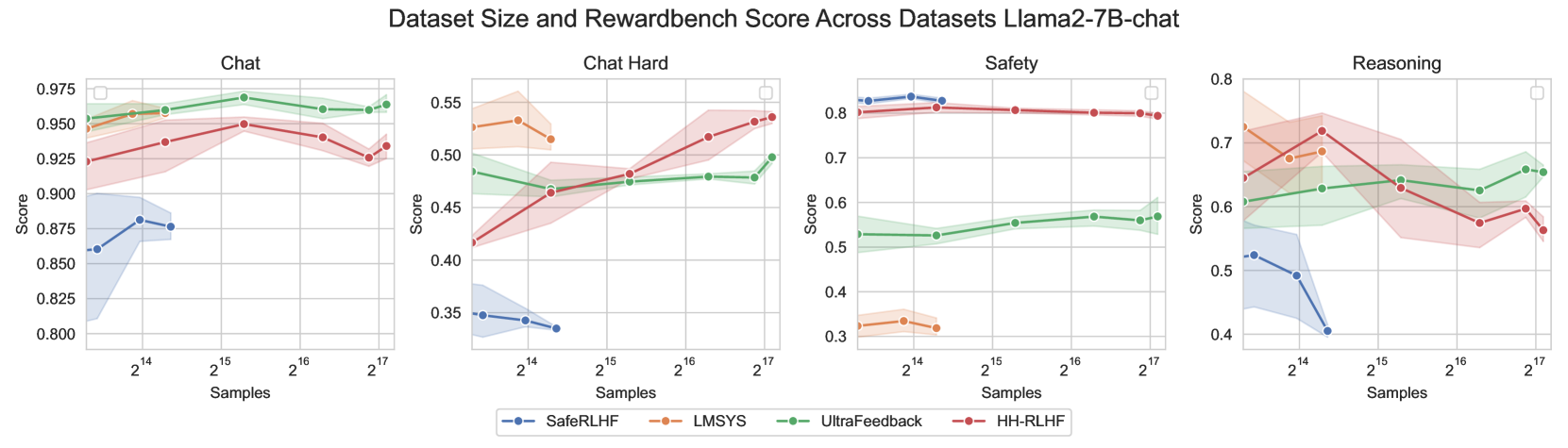
RewardBench performance (Accuracy) vs Training Set Size for different task categories (Chat, Reasoning, Safety).
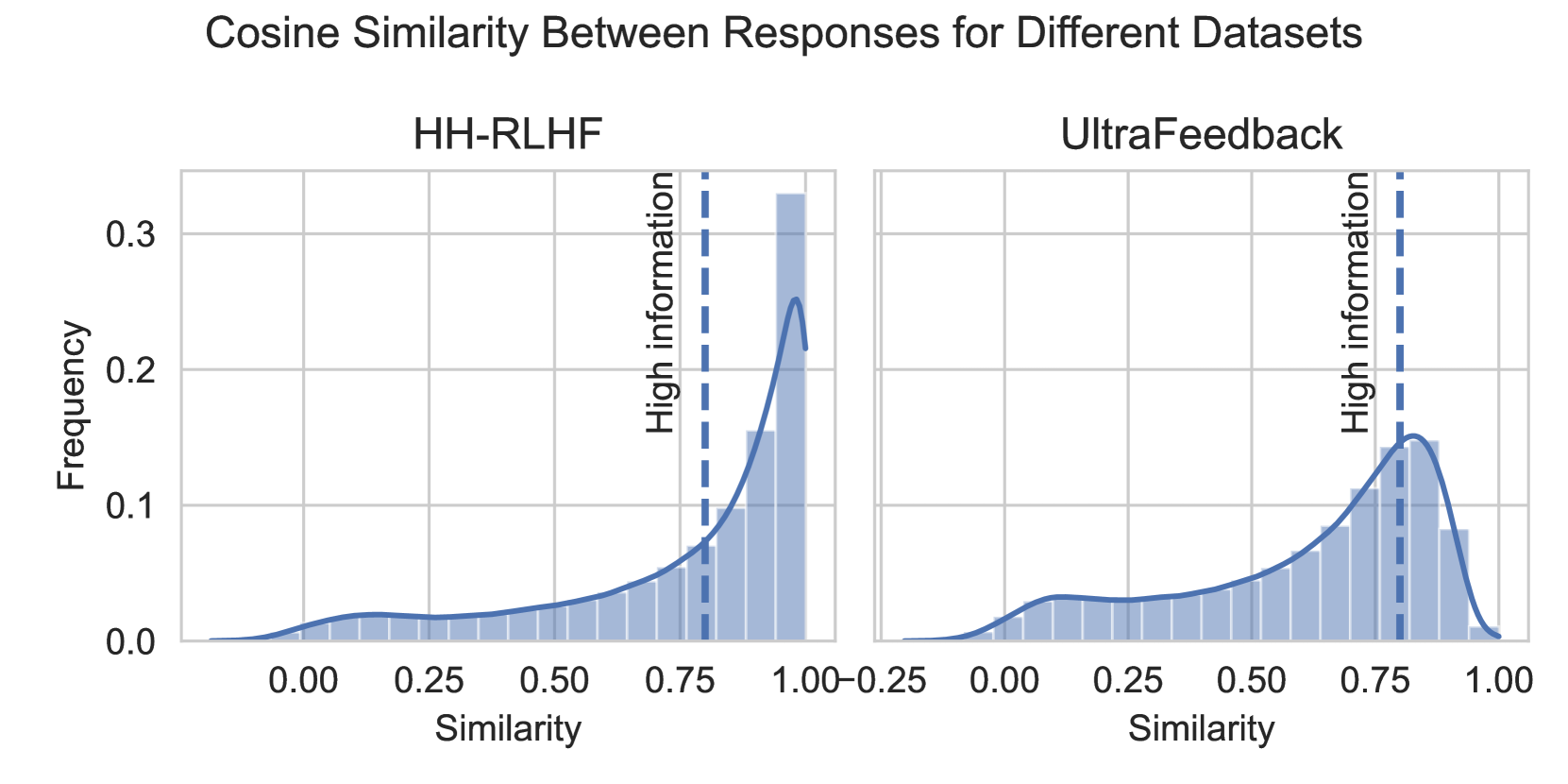
Performance comparison between Random Sampling vs. High Information Sampling (low cosine similarity) for different model sizes.
Main Takeaways
- Dataset composition is more critical than scale for Reward Benchmarks; specific datasets dominate specific categories (e.g., SafeRLHF for Safety) regardless of size
- Reward models exhibit high 'Noise Invariance', maintaining accuracy even when significant portions (30-40%) of labels are incorrect
- Training on 'high information' examples (dissimilar responses) is particularly beneficial for smaller reward models (e.g., 350M parameters), while larger models are more robust to low-information data
- HH-RLHF and LMSYS datasets tend to collapse to uncertain predictions (P approx 0.5) faster than UltraFeedback when noise is introduced, suggesting higher baseline noise