📝 Paper Summary
Deductive Reasoning
RLHF Data Synthesis
MuseD is a scalable data synthesis method that generates formal logic problems with verifiable reasoning steps, enabling dense reward signals for RLHF that significantly improve model reasoning capabilities.
Core Problem
Training LLMs for multi-step deductive reasoning is difficult because existing data lacks verifiable step-by-step supervision, and generating contradiction-free formal logic prompts with scalable complexity is challenging.
Why it matters:
- Current reasoning datasets often rely on outcome supervision, which fails to correct flawed reasoning processes (hallucinations or logical leaps) leading to correct answers by chance
- Manual creation of rigorous multi-step logic problems is expensive and unscalable, limiting the amount of high-quality training data available for alignment
Concrete Example:
Given premises 'Cats are mammals' and 'Mammals are animals', a model might conclude 'Cats are animals' using common sense shortcuts rather than logic. MuseD uses virtual entities (e.g., 'Alpha is Beta') to force actual deductive reasoning and verifies the specific elimination of middle terms.
Key Novelty
Multi-step Deduction (MuseD) Data Synthesis & Step-Level Scoring
- Backward generation of logic trees: Starts from a conclusion and recursively adds premises using valid syllogisms to guarantee contradiction-free, solvable prompts with controllable complexity
- Step-level verification: Scores reasoning chains by tracking the elimination of 'middle terms' (logical connectors), ensuring the model actually performed the deduction steps rather than guessing
Architecture
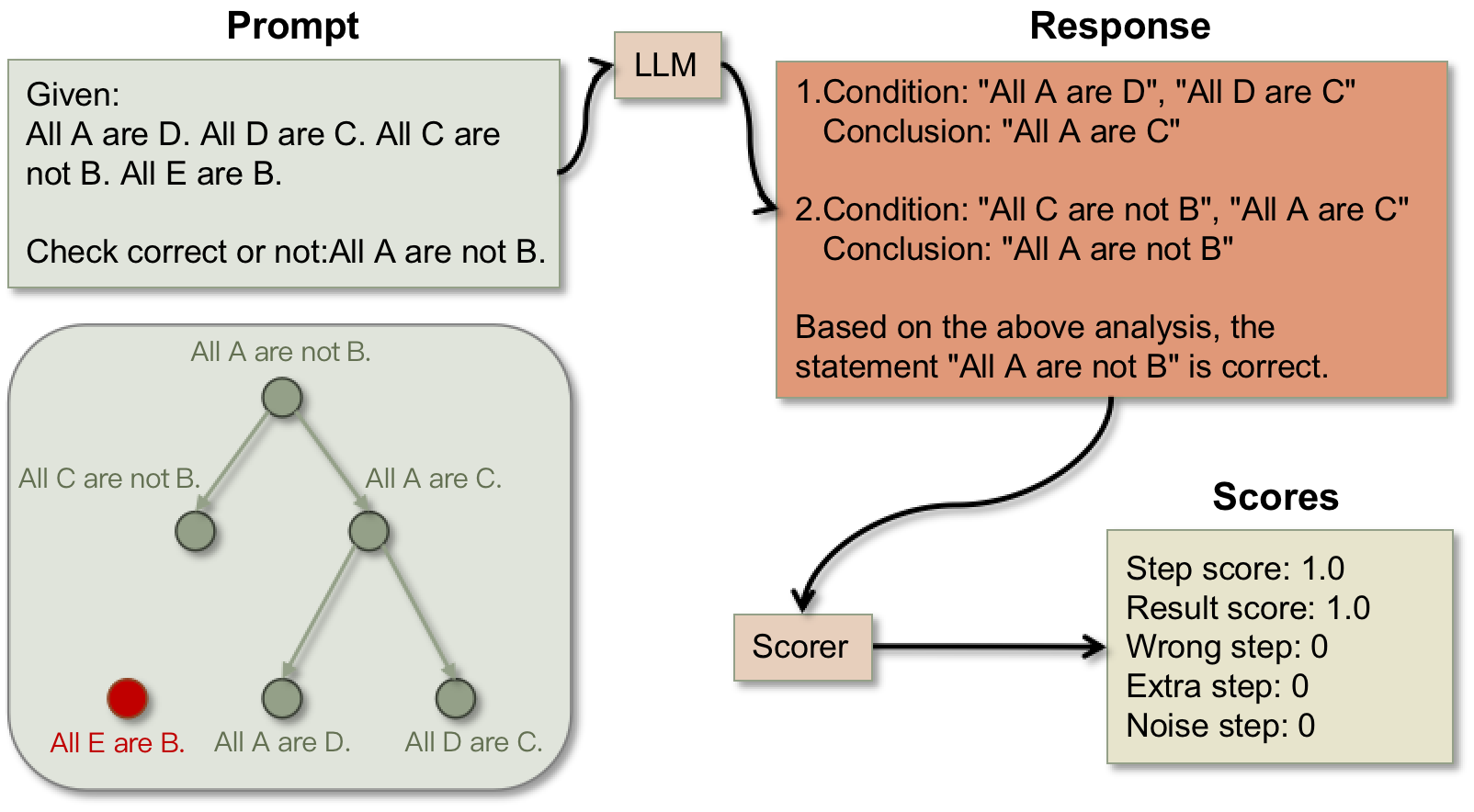
The MuseD data generation pipeline: Backward generation of the logic tree followed by forward entity filling.
Evaluation Highlights
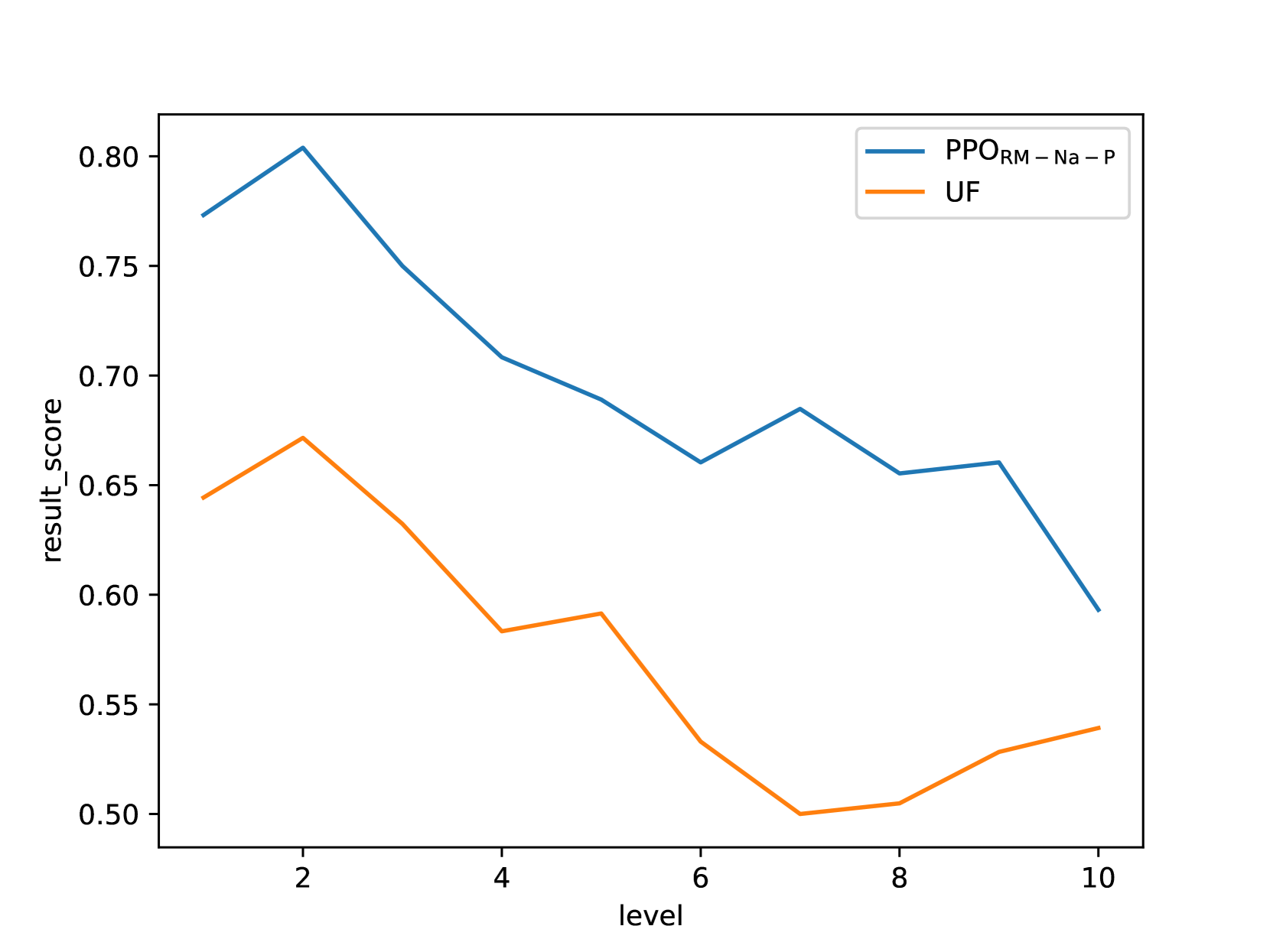
- RLHF with MuseD data improves Llama-3-8B-Instruct performance by +15.5% on the out-of-domain FOLIO benchmark compared to the base model
- Achieves +30.5% improvement on the in-domain MuseD test set compared to the base model
- Step-level rewards (Process + Outcome) outperform Outcome-only rewards by ~10% on difficult reasoning tasks (10-step depth)
Breakthrough Assessment
7/10
Strong methodology for synthetic data generation in formal logic. The step-level scoring mechanism is verifiably correct by design, addressing a major bottleneck in process supervision for reasoning.