📝 Paper Summary
Reinforcement Learning from AI Feedback (RLAIF)
Language Model Alignment
Scalable Oversight
RLAIF achieves performance comparable to RLHF on summarization and dialogue tasks by using off-the-shelf LLMs to generate preference labels, eliminating the need for human annotation.
Core Problem
RLHF relies on high-quality human preference labels, which are expensive, time-consuming, and difficult to scale.
Why it matters:
- Human annotation is a major bottleneck for aligning large language models
- Scaling supervision is critical as models become more capable and complex
- Existing methods do not confirm if AI feedback can fully replace human feedback for RL training
Concrete Example:
Training a helpful assistant requires thousands of human ratings on which response is better. Collecting these labels limits how much RL training can be done, whereas an AI labeler can generate unlimited labels instantly.
Key Novelty
Reinforcement Learning from AI Feedback (RLAIF) and Direct RLAIF (d-RLAIF)
- Replace human annotators with an off-the-shelf LLM that rates response pairs, then train a Reward Model on these AI preferences
- Introduce d-RLAIF, which skips Reward Model training by using the LLM to score responses directly during the RL update loop
- Demonstrate 'self-improvement' where the AI labeler is the same size or even the exact same checkpoint as the policy being trained
Architecture
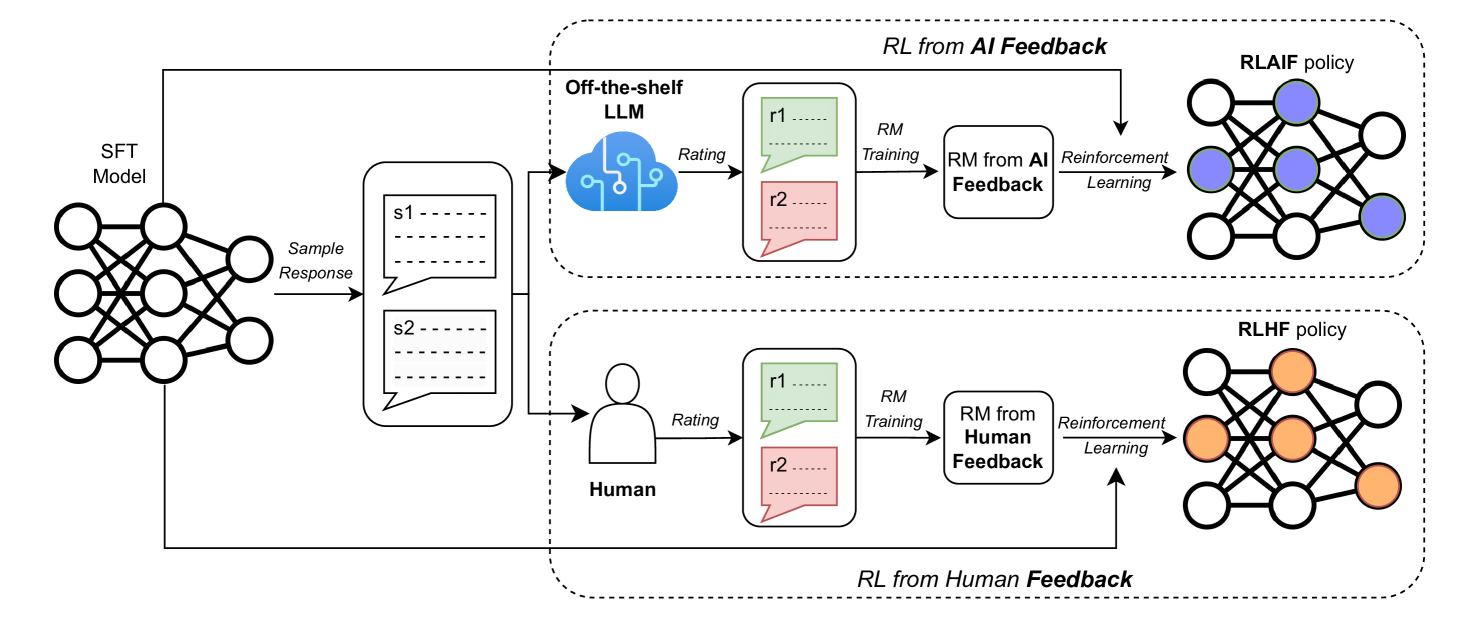
Comparison of Canonical RLAIF vs. Direct RLAIF (d-RLAIF) workflows.
Evaluation Highlights
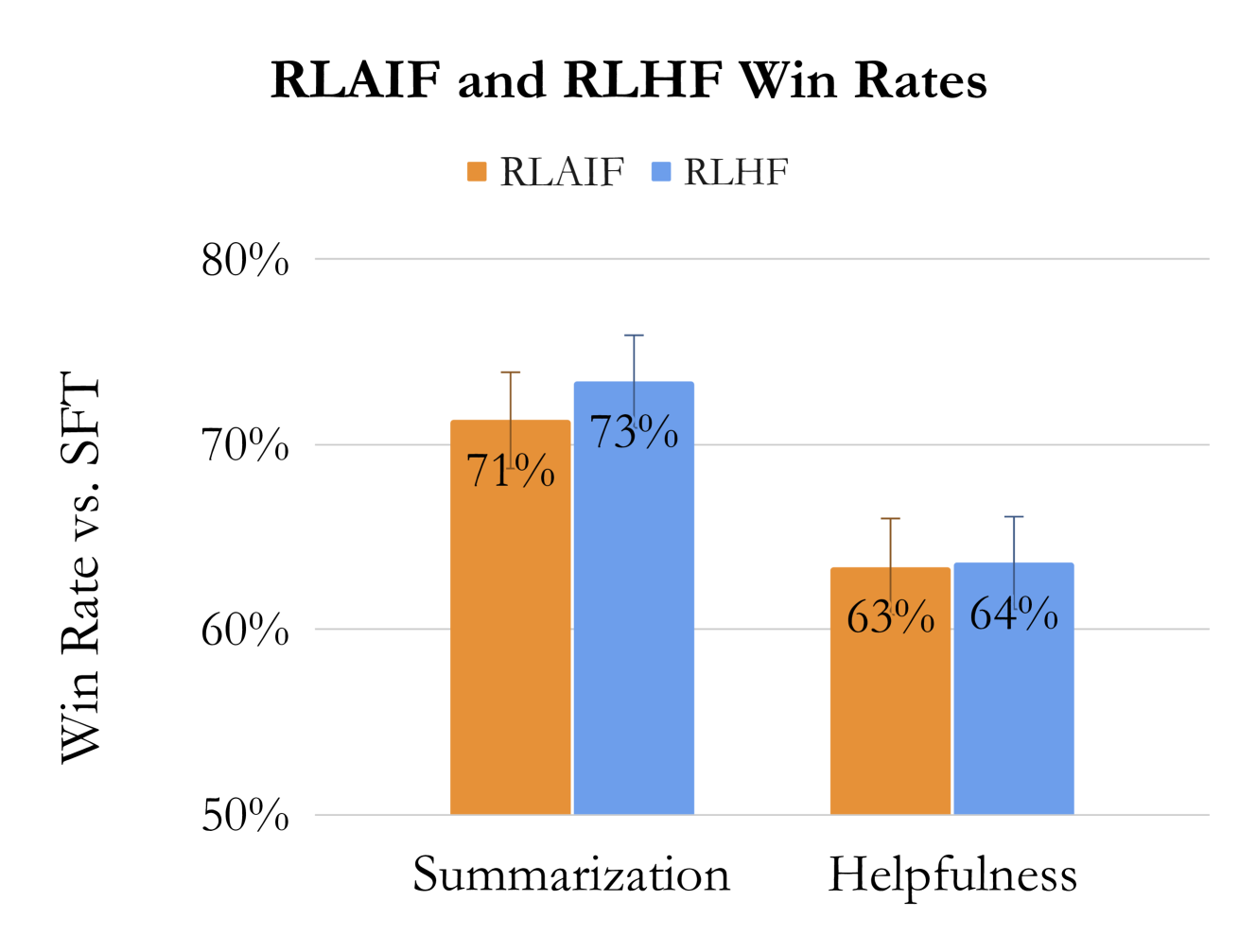
- RLAIF matches RLHF performance: 50% win rate between the two policies across summarization and helpful dialogue tasks
- RLAIF outperforms SFT baseline with 71% win rate on summarization and 63% on helpful dialogue
- On harmless dialogue, RLAIF achieves an 88% harmless rate, outperforming RLHF (76%) and SFT (64%)
Breakthrough Assessment
9/10
Strongly demonstrates that expensive human feedback can be replaced by AI feedback without performance loss, a critical finding for scaling model alignment.