📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
LLM Alignment
DAR replaces conflicting stability constraints in RLHF with a unified dual-KL objective, solvable via iterative weighted regression that balances the reference model and current policy.
Core Problem
Current RLHF methods enforce stability and reference regularization as separate, conflicting constraints (clipping vs. current policy, penalty vs. initialization), creating an overly restrictive intersection that excludes high-reward policies.
Why it matters:
- The shrinking intersection of trust regions prevents the policy from reaching optimal solutions that require significant behavioral shifts
- Implicit trade-offs between preventing reward hacking and maintaining optimization stability are under-explored, leading to suboptimal alignment
- PPO's separate constraints become increasingly conflicting as the model drifts from initialization, causing performance stagnation
Concrete Example:
In standard PPO, policy updates are clipped to stay close to the current policy ($\pi_t$) while also being penalized for diverging from the base model ($\pi_0$). If a high-reward strategy lies outside the narrow intersection of these two distinct trust regions (e.g., requires a large stable shift), the optimizer cannot reach it, whereas a unified objective would allow exploration.
Key Novelty
Dual-regularized Advantage Regression (DAR)
- Unifies the two primary RLHF constraints (stability and reference) into a single objective with dual KL-divergence penalties
- Demonstrates that this dual-KL objective is equivalent to regularizing against a dynamic, interpolated reference target that moves toward the optimal policy
- Reformulates the RL problem as an iterative weighted supervised fine-tuning (SFT) task, removing the need for complex PPO gradient updates
Architecture
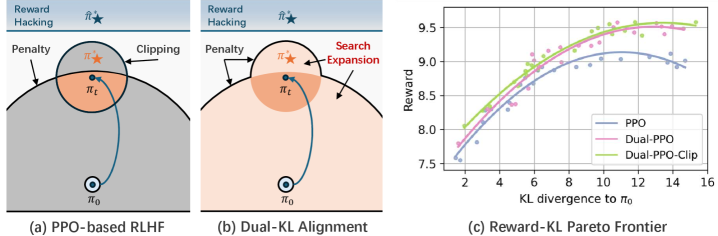
Conceptual visualization of the Dual-KL regularization objective compared to standard PPO constraints.
Evaluation Highlights
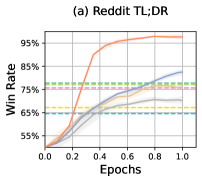
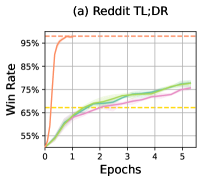
- Outperforms state-of-the-art online RLHF baseline GRPO by +7.27% in mean reference win rate (92.42% vs 85.15%) across three alignment tasks
- Achieves superior sample efficiency compared to Direct Alignment from Preference (DAP) methods, converging with approximately half the annotations
- Consistently surpasses online preference optimization methods (DPO, IPO, SLiC) in win rates, validating the benefit of advantage-based optimization
Breakthrough Assessment
8/10
The paper theoretically resolves a fundamental conflict in RLHF formulation and provides a simplified, regression-based algorithm that empirically beats dominant baselines like PPO and DPO.