📝 Paper Summary
RLHF System Optimization
Large Language Model Training
DeepSpeed-Chat introduces a Hybrid Engine that unifies high-performance inference and training optimizations into a single system, accelerating RLHF training by over 15x compared to existing frameworks.
Core Problem
Training ChatGPT-like models via RLHF is computationally expensive and inefficient because existing systems struggle to optimize the alternating inference (generation) and training phases, often utilizing less than 5% of hardware capabilities.
Why it matters:
- The high cost and multi-GPU requirements of RLHF prevent most researchers from training models larger than 6B parameters, limiting democratization.
- Existing pipelines treat generation and training separately, failing to leverage specific optimizations (like inference kernels) during the generation phase, which creates a massive bottleneck.
- Current solutions (e.g., Colossal-AI) lack the memory efficiency to support large models (e.g., 66B+) on accessible hardware clusters.
Concrete Example:
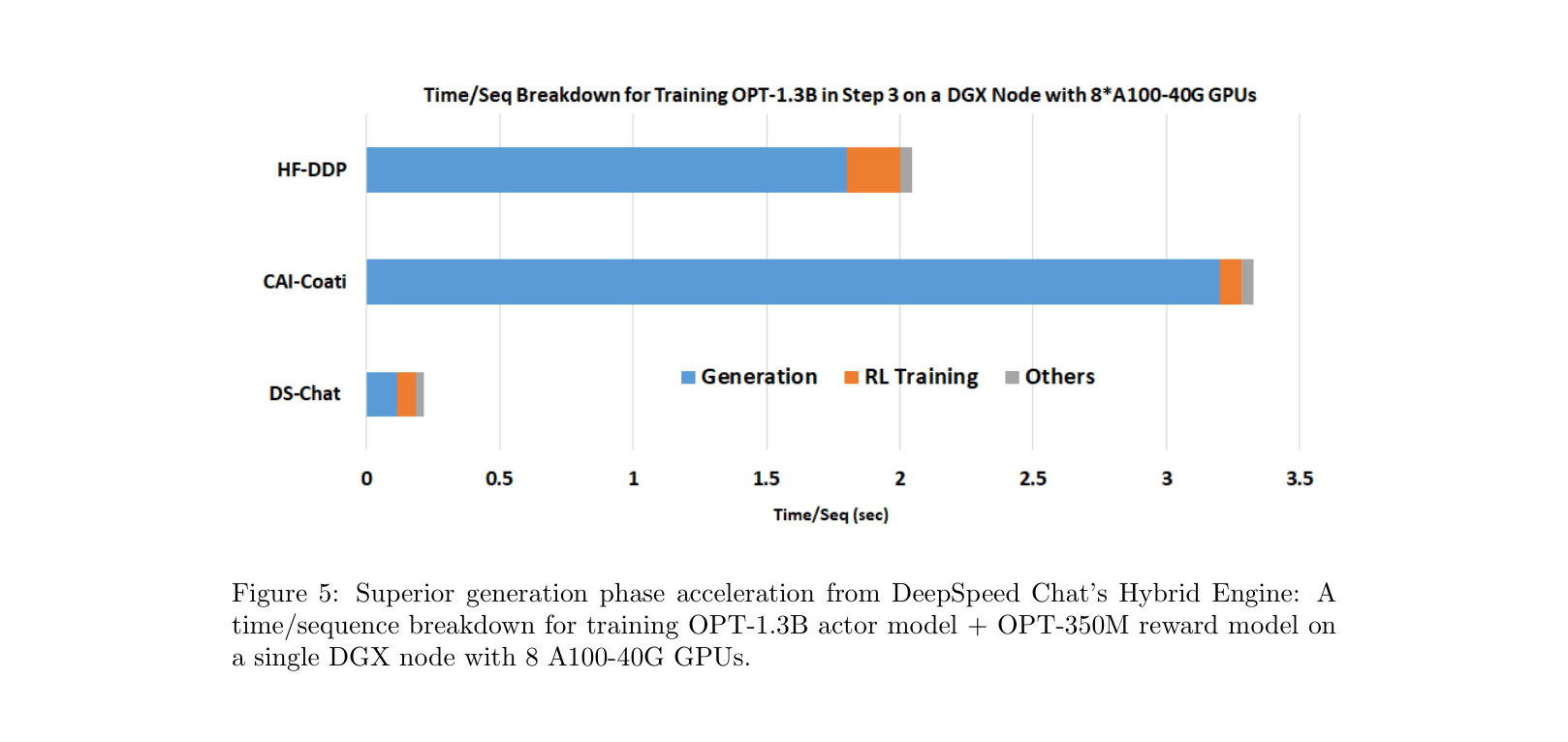
Training a 6.7B parameter model typically requires an expensive multi-GPU setup, yet standard systems achieve <5% efficiency. Specifically, the generation phase (Step 3) requires running the actor model repeatedly, which becomes memory-bandwidth bound and slow without dedicated inference kernels.
Key Novelty
DeepSpeed Hybrid Engine (DeepSpeed-HE)
- Seamlessly switches between a high-performance Inference Engine (for token generation) and a Training Engine (for parameter updates) within the RLHF loop.
- Dynamically applies different optimizations—Tensor Parallelism and specialized kernels for generation, ZeRO sharding and LoRA for training—to maximize throughput in each phase.
- Uses a unified memory management system to handle KV-caches and intermediate results, avoiding reallocation bottlenecks during mode transitions.
Architecture
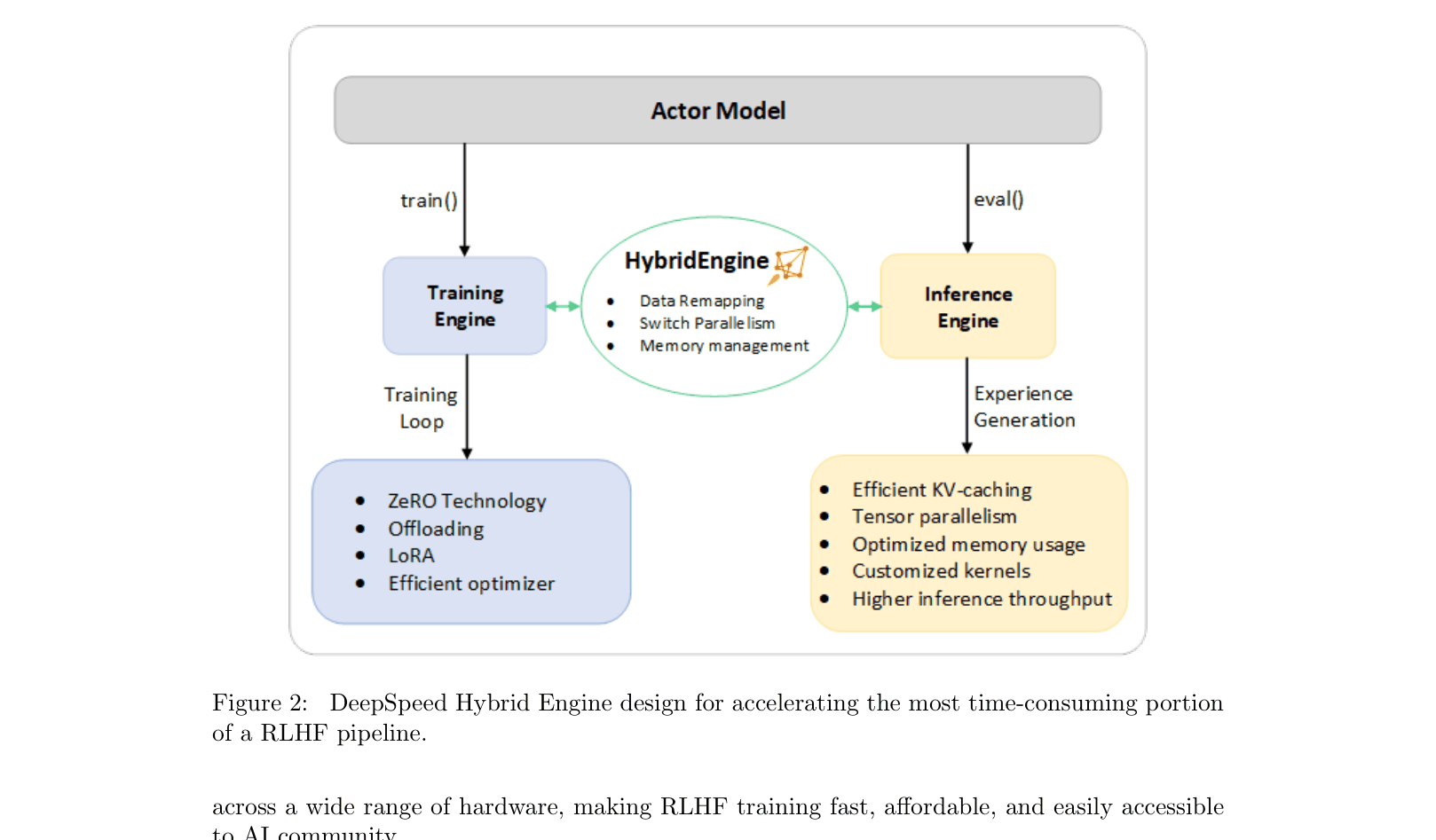
The DeepSpeed Hybrid Engine architecture, showing how it unifies inference and training.
Evaluation Highlights
- >15x faster training throughput for RLHF Step 3 compared to Colossal-AI and HuggingFace DDP baselines.
- Enables training an OPT-13B model in just 9 hours on a single node of 8x A100-80GB GPUs for approximately $290.
- Scales to train a massive OPT-175B model in under 20 hours on 64x A100-80GB GPUs.
Breakthrough Assessment
9/10
Significantly lowered the barrier to entry for RLHF by making it affordable and fast. The Hybrid Engine's unification of inference and training is a major system design improvement.