📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Distributed Systems for AI
OpenRLHF accelerates RLHF training by decoupling inference and training modules via Ray, using vLLM for fast generation and DeepSpeed for efficient parallel training.
Core Problem
RLHF training is severely bottlenecked by the inference phase (often >90% of runtime), especially for long Chain-of-Thought tasks, while existing frameworks force a trade-off between ease of use and high-performance scalability.
Why it matters:
- Modern reasoning models require generating long Chain-of-Thought (CoT) sequences during training, which cripples standard training loops
- Industrial frameworks like Nemo-aligner are powerful but complex and tightly coupled, creating barriers for academic researchers
- Accessible frameworks like TRL or DeepSpeed-Chat often lack sophisticated orchestration for large-scale distributed training or fail to optimize the critical inference step
Concrete Example:
In a long Chain-of-Thought (CoT) RLVR scenario, a model must generate thousands of tokens per step. A synchronous framework like DeepSpeed-Chat halts training while waiting for slow generation, wasting GPU resources. OpenRLHF allows generation (via vLLM) and training to run asynchronously on specialized engines.
Key Novelty
Ray-based Decoupled Architecture with Asynchronous Dataflow
- Assigns distinct roles (Rollout Engine, Actor Engine, Critic Engine) to different GPU groups managed by Ray, rather than running all tasks monolithically on all GPUs
- Integrates vLLM specifically for the rollout phase to leverage PagedAttention and continuous batching, drastically speeding up the generation bottleneck
- Supports asynchronous communication where engines process data immediately upon availability via message passing, preventing the whole pipeline from stalling on the slowest task
Architecture
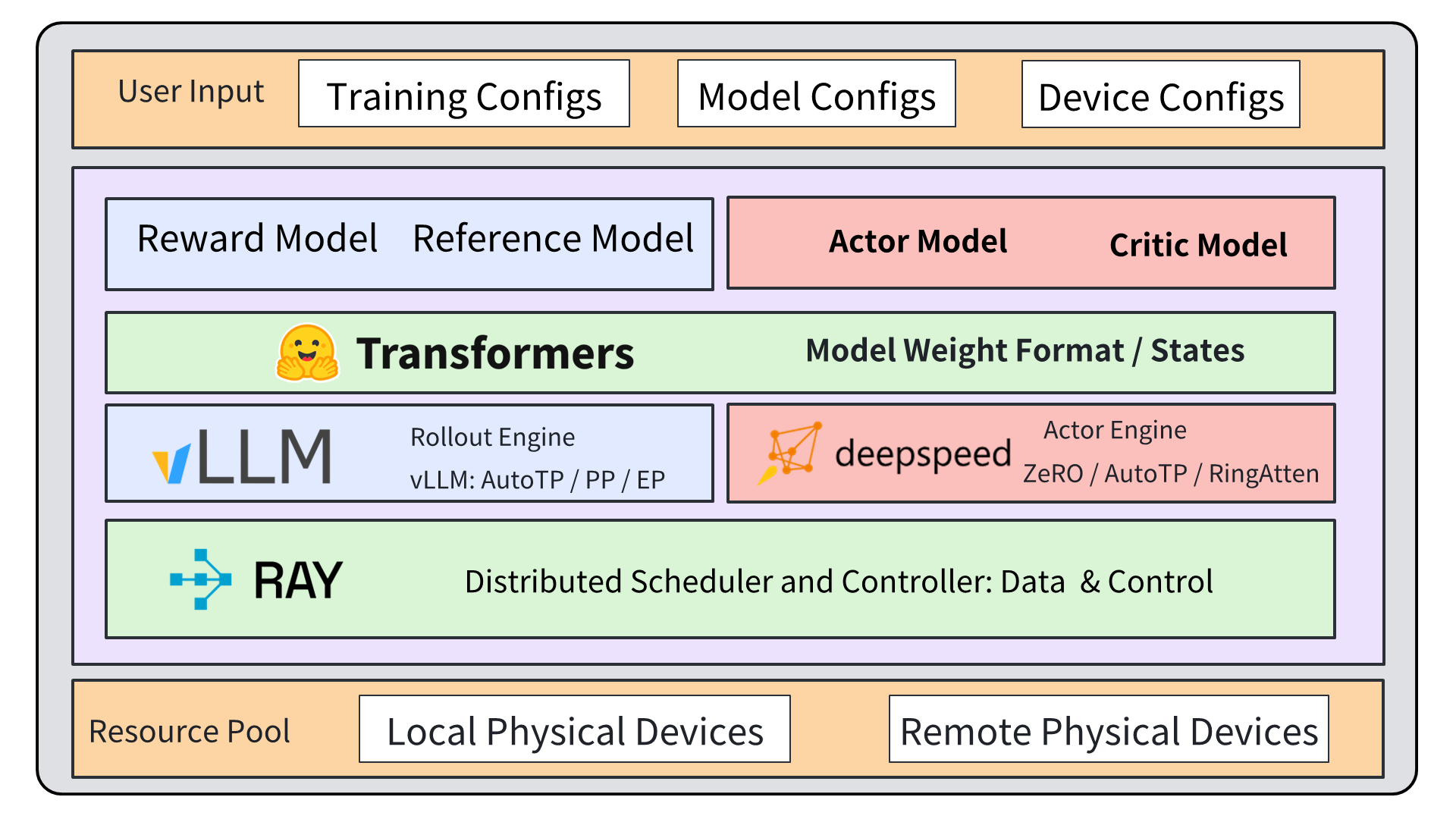
The Ray-based orchestration architecture of OpenRLHF, illustrating the separation of duties between Rollout, Actor, and Critic engines.
Evaluation Highlights
- 1.56× speedup over state-of-the-art framework verl on 14B parameter models with 8K context length (328.6 vs. 511.1 seconds per step)
- 3.1× speedup over TRL on GSM8K benchmark using GRPO (1,657 vs. 5,189 seconds for one epoch)
- 3.6× speedup over DeepSpeed-Chat on PPO training with 1,024 prompts (236.8 vs. 855.09 seconds)
Breakthrough Assessment
9/10
Addresses the critical inference bottleneck in RLHF with a clean, open-source architectural solution (Ray + vLLM + DeepSpeed) that is both highly performant and accessible.