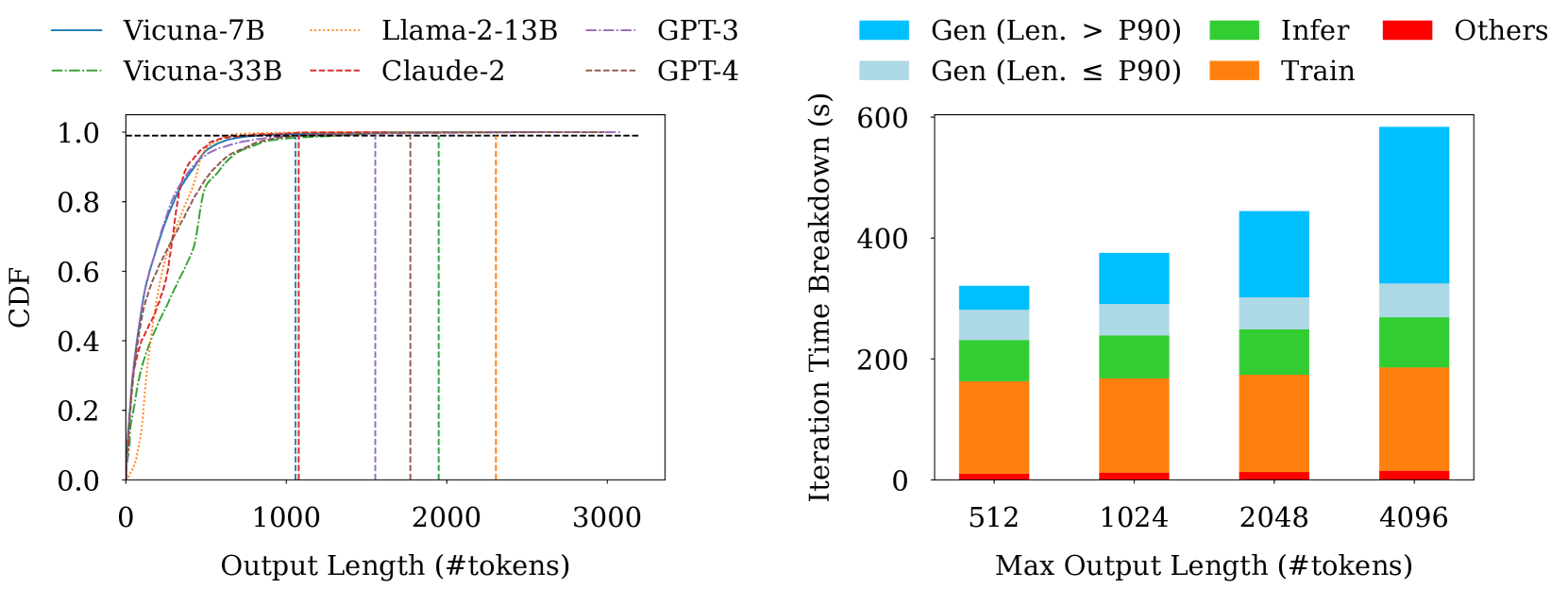📝 Paper Summary
RLHF System Efficiency
Distributed Training
GPU Utilization
RLHFuse improves RLHF training throughput by decomposing tasks into subtasks to enable inter-stage fusion (overlapping generation/inference) and intra-stage fusion (interleaving Actor/Critic training pipelines).
Core Problem
RLHF training suffers from low GPU utilization due to data skewness (long-tail generation blocking inference) and pipeline bubbles (idle time in pipeline parallelism) during the training stage.
Why it matters:
- Current frameworks treat RLHF tasks as atomic units, missing optimization opportunities within the internal structure of tasks
- Long-tail samples (top 0.1%) can dominate generation time, forcing most GPUs to sit idle while waiting for the longest response to finish
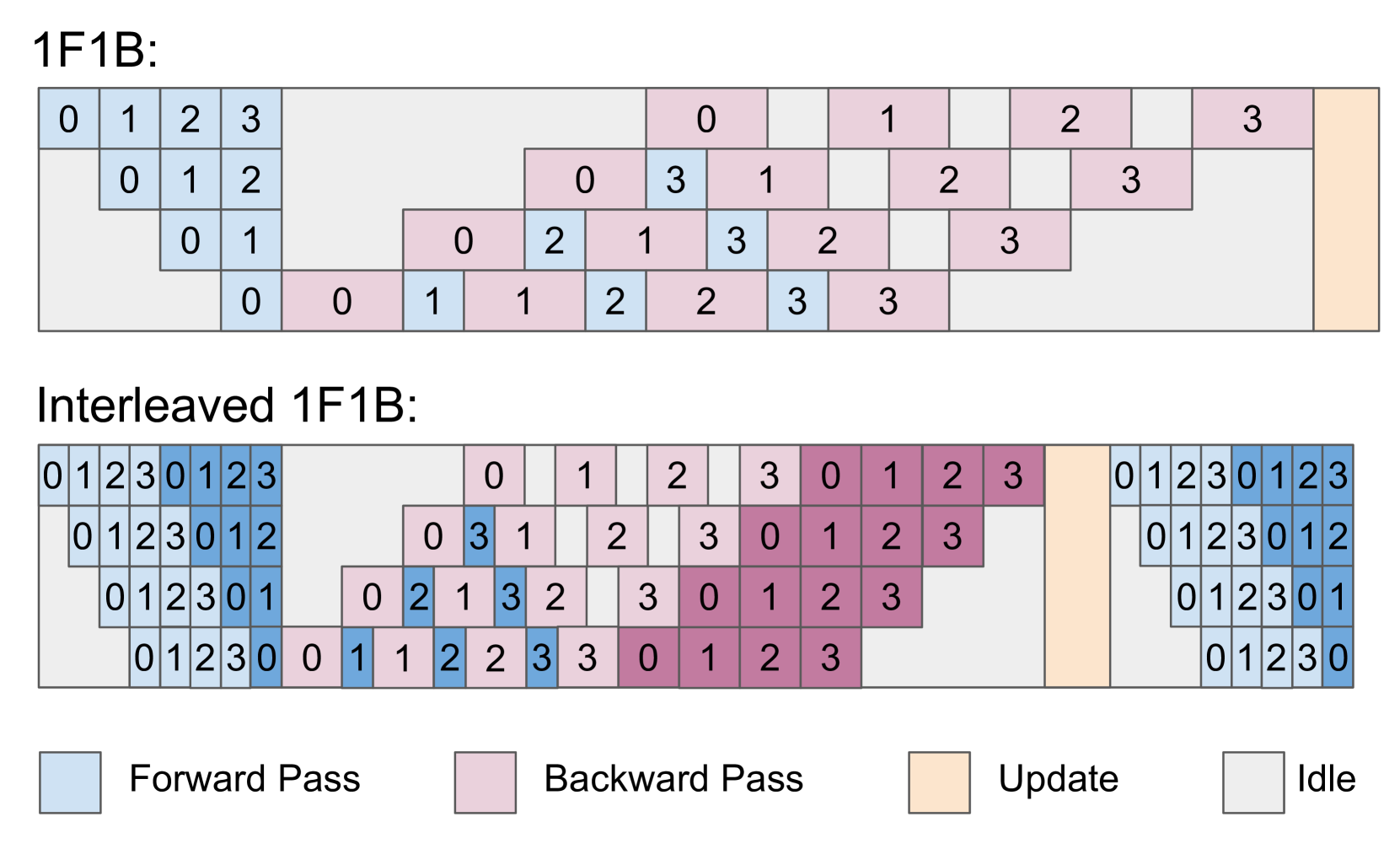
- As models scale to hundreds of billions of parameters requiring large Pipeline Parallelism (PP) sizes, pipeline bubbles can waste ~50% of training resources
Concrete Example:
In the LMSYS-Chat-1M dataset, the 99.9th percentile output length is >10x the median. During generation, once 99% of samples finish, the entire inference stage is blocked waiting for the final 1% of long samples to complete on just a few GPUs, leaving the rest idle.
Key Novelty
Subtask-level Stage Fusion (RLHFuse)
- **Data-aware Inter-stage Fusion:** dynamic migration of long-tail samples to a subset of GPUs during generation, allowing the freed GPUs to immediately start the dependent inference tasks
- **Model-aware Intra-stage Fusion:** utilizes a bidirectional pipeline schedule to train the Actor and Critic models simultaneously on the same GPUs, using one model's computation to fill the other's pipeline bubbles
Architecture
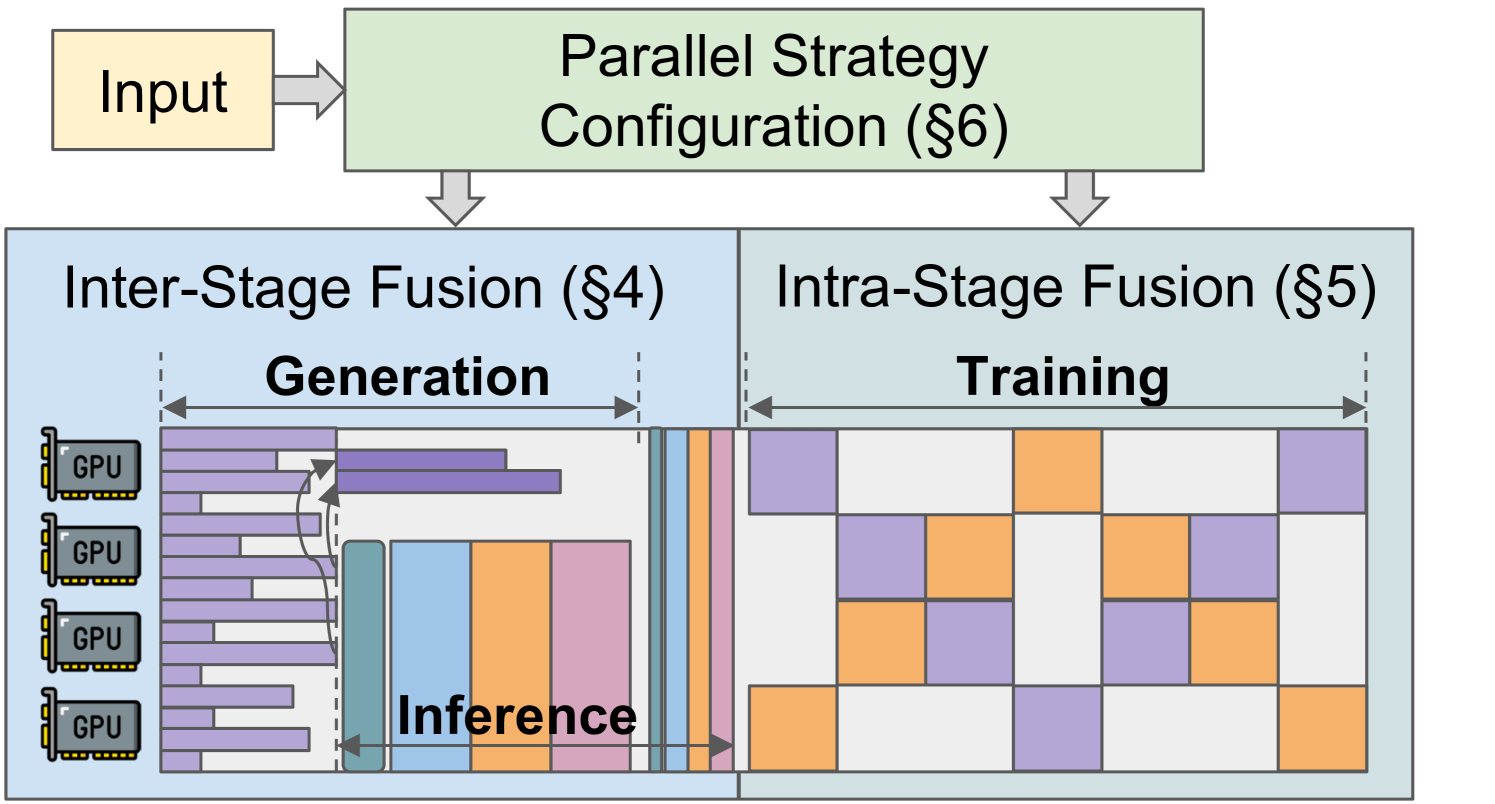
Overview of RLHFuse illustrating Inter-stage and Intra-stage fusion.
Evaluation Highlights
- Increases RLHF training throughput by up to 3.7x compared to existing systems (state-of-the-art frameworks)
- Reduces the impact of long-tail generation latency where the longest samples account for >50% of generation time in large models
- Effectively mitigates pipeline bubbles which typically consume ~50% of cycles in standard 1F1B schedules for large models
Breakthrough Assessment
8/10
Addresses two fundamental efficiency bottlenecks in RLHF (skew and bubbles) with a novel system-level scheduling approach, offering significant throughput gains without altering model semantics.